Диктофон в текст на iPhone и Android: пошагово в 2026
Как перевести запись диктофона в текст на айфоне и Android прямо с телефона: Voice Memos, Samsung Galaxy AI, Telegram и облачный Whisper на русском.
Запись с диктофона переводится в текст за 3-7 минут на современных сервисах распознавания речи. Из российского устройства (iPhone Voice Memos, Android Recorder, Telegram-голосовое) файл копируется в формате M4A, AMR или OGG, перетаскивается в облачный сервис на Whisper Large-v3-turbo (Диктуй на Win+Mac с рублёвой оплатой, TurboScribe для разовых задач) и через несколько минут возвращается готовый текст. Точность на чистой русской речи 95-98%, на интервью с шумом 88-93%. Бесплатный тариф Диктуй закрывает 30 минут навсегда без карты; для регулярной — подписка от 299 ₽/мес.
В пятницу мне знакомая журналистка прислала в Telegram сообщение: «Нужно расшифровать двухчасовое интервью с экспертом, дедлайн в понедельник. Я обычно набираю с диктофона руками, выходит выходные две — на этой неделе нет ресурса. Что есть быстрого?». Это типичный звонок, по которому видно — у журналистов выходных не отнимают, а вот восемь часов работы можно вернуть за один скачанный M4A.
Расшифровка диктофонной записи в 2026 году — это уже не услуга за деньги ($1-3 за минуту у людей-расшифровщиков), а стандартная операция за пять минут. Whisper Large-v3-turbo от OpenAI закрывает 95-98% точности на чистой русской речи, и десяток сервисов на этой модели делают drag-and-drop'ом без кода. В этом гайде — пошагово, что делать с записью с iPhone, Android или Telegram-голосового, какой сервис выбрать под задачу и где у каждого тонкие места.
Дисклеймер: я делаю Диктуй — российский сервис голосового ввода и транскрибации. В сравнительной таблице ниже мой продукт идёт первым по приоритету для русскоязычной аудитории с рублёвой оплатой, но я отметил три прямых конкурента и сценарии, где они выигрывают по конкретным фичам. Цифры по точности и скорости проверяемы — поставьте бесплатные 30 минут в любом сервисе и прогоните одну свою запись.
Какие форматы у диктофонов и почему это важно
Запись с разных устройств приходит в разных форматах, и половина проблем с расшифровкой начинается на этапе загрузки файла — сервис не принимает контейнер, или принимает, но криво распознаёт.
iPhone Voice Memos пишет в M4A с кодеком AAC по умолчанию. Это стандартный формат, его принимает любой облачный сервис. С iOS 17+ доступна опция Lossless (несжатый WAV) для тех, кому критична максимальная точность на тихих записях с дальним микрофоном. Размер часовой записи в M4A — около 30-50 МБ.
Android-диктофоны — зоопарк. Стандартное приложение Recorder на Pixel пишет в M4A, как iPhone. Samsung Voice Recorder — в M4A или AMR в зависимости от настройки. Старые модели и часть Xiaomi — в AMR (низкий битрейт, заточенный под голос для телефонной записи). Часть кастомных диктофонных приложений — в OGG/Opus или WAV. Совет: до записи проверьте в настройках приложения, в какой формат сохраняется файл, и поставьте M4A или WAV. Это снимает 80% будущих проблем.
Telegram-голосовые сообщения — OGG с кодеком Opus. Кодек хорош для речи (изначально под VoIP оптимизирован), но не все сервисы транскрибации его принимают напрямую. Диктуй и TurboScribe принимают OGG; ряд других сервисов требует предварительной конвертации в M4A.
Профессиональные диктофоны (Zoom H5, Tascam DR-05, Sony PCM-A10) пишут в WAV или MP3 — оба универсально совместимы. Дополнительно у некоторых моделей есть DSS (Digital Speech Standard) — устаревший формат от Olympus и Philips, который придётся конвертировать.
Конвертация любого экзотического в M4A — одна команда ffmpeg:
ffmpeg -i recording.amr -c:a aac output.m4a
Для AMR/DSS/3GP это снимает все проблемы с приёмом файла. Качество речи не страдает: AMR изначально содержит меньше информации, чем M4A способен сжать.
Шаг 1. Скопировать запись с устройства на компьютер
Самая раздражающая часть процесса — у каждой ОС свой путь.
iPhone → Mac через AirDrop: открыли Voice Memos, выбрали запись, кнопка Поделиться, AirDrop, через 3-5 секунд файл на Mac. iPhone → Windows через iCloud Drive: в Voice Memos «Сохранить в Файлы» → iCloud Drive → синхронизация Windows-клиентом iCloud (или web-доступ через icloud.com).
Android → ПК через USB-кабель: подключили в режиме MTP, нашли в /Recordings или /Recorder/ свой файл, скопировали. Альтернативы: загрузить в Google Drive с самого устройства, скачать на ПК. Или воспользоваться Snapdrop / LocalSend для прямой передачи через локальную сеть.
Telegram-голосовое → файл: длинное нажатие на голосовое (iOS) или нажатие меню (Android) → Сохранить в Файлы / Скачать. На десктопном клиенте Telegram — правый клик → Сохранить как.
Профессиональный диктофон: USB-подключение, открыли как обычный диск, скопировали .WAV или .MP3 файл. На современных моделях есть Bluetooth-выгрузка в приложение производителя.
Шаг 2. Подготовить файл к загрузке
Перед загрузкой проверяю три вещи: формат, длительность, аудиодорожку.
Длительность. Большинство облачных сервисов берут файлы до 2 часов или до 500 МБ за один upload. Если интервью три-четыре часа (бывают такие, особенно у журналистов с длинными разговорами) — режу на части ffmpeg одной командой:
ffmpeg -i input.m4a -ss 00:00:00 -t 01:30:00 -c copy part1.m4a
Эта строка делает копию первых полутора часов без перекодирования — занимает 5-10 секунд, не часы.
Аудиодорожка. Бывает, что после копирования файл оказывается без звука или с пустым каналом. Запускаю в плеере 30 секунд — слышу ли. Если в одном канале (например, после неудачной записи через стереомикрофон, где работала одна сторона) — конвертирую в моно командой ffmpeg -i input.m4a -ac 1 output.m4a. Облачный сервис не вернёт «у тебя плохой звук» — он попробует распознать пустоту, спишет минуты с лимита и отдаст пустой текст.
Формат. Проверил по списку выше — если AMR/DSS/3GP, конвертирую в M4A через ffmpeg. Остальные стандартные форматы (M4A, MP3, WAV, OGG, FLAC) принимаются напрямую большинством сервисов.
Шаг 3. Выбрать сервис под задачу
Не люблю формат «топ-10 сервисов транскрибации» — это редко помогает выбрать. Давайте по сценарию. Если же вы ещё выбираете между живой диктовкой и расшифровкой готового файла, обзорный гайд «Голос в текст: 5 способов» раскладывает все маршруты речь-в-текст по задачам.
| Что у вас за запись | Что выбрать |
|---|---|
| Разовое интервью на 1-2 часа, нужна диаризация | Sonix ($10 за час файла) или Riverside для live-записи |
| Регулярная работа с диктофоном — лекции, интервью | Десктоп с подпиской — Диктуй Pro 299 ₽/мес |
| Telegram-голосовое раз в неделю, не больше | Диктуй Free 30 минут навсегда |
| Шумная запись с улицы или зала | Audacity (Noise Reduction) или Adobe Podcast Enhance перед любым Whisper-сервисом |
| Большой объём (десятки часов в месяц) | Whisper API через Groq, $0.04 за час аудио |
| Только разовая задача и не страшно платить в долларах | TurboScribe (30 мин/день бесплатно) |
Подробное сравнение восьми сервисов транскрибации с реальными цифрами WER на разных условиях — в отдельной статье «Транскрибация аудио в текст: сравнение 8 сервисов». Здесь — короткое резюме для диктофонного сценария: на чистой русской речи Диктуй (Whisper Large-v3-turbo через Groq) и TurboScribe дают сопоставимую точность 92-97%, расходятся по платформе, цене (рублёвая vs валютная оплата) и поддержке диаризации (Sonix, Riverside если нужна).
Что я рекомендую большинству: возьмите 30 минут бесплатно у Диктуй (без карты, без регистрации) или 30 минут в день у TurboScribe (если есть валютная карта), прогоните одну свою реальную запись с диктофона. Точность измеряйте на своих файлах, не на чужих обзорах — у каждого свой микрофон, манера речи и доменная лексика.
Готовы сразу попробовать на собственной записи? — скачать Диктуй, 30 минут бесплатно навсегда без регистрации карты. Прогоните одну свою запись и сравните точность с тем, что обещают листинги.
Шаг 4. Распознать запись
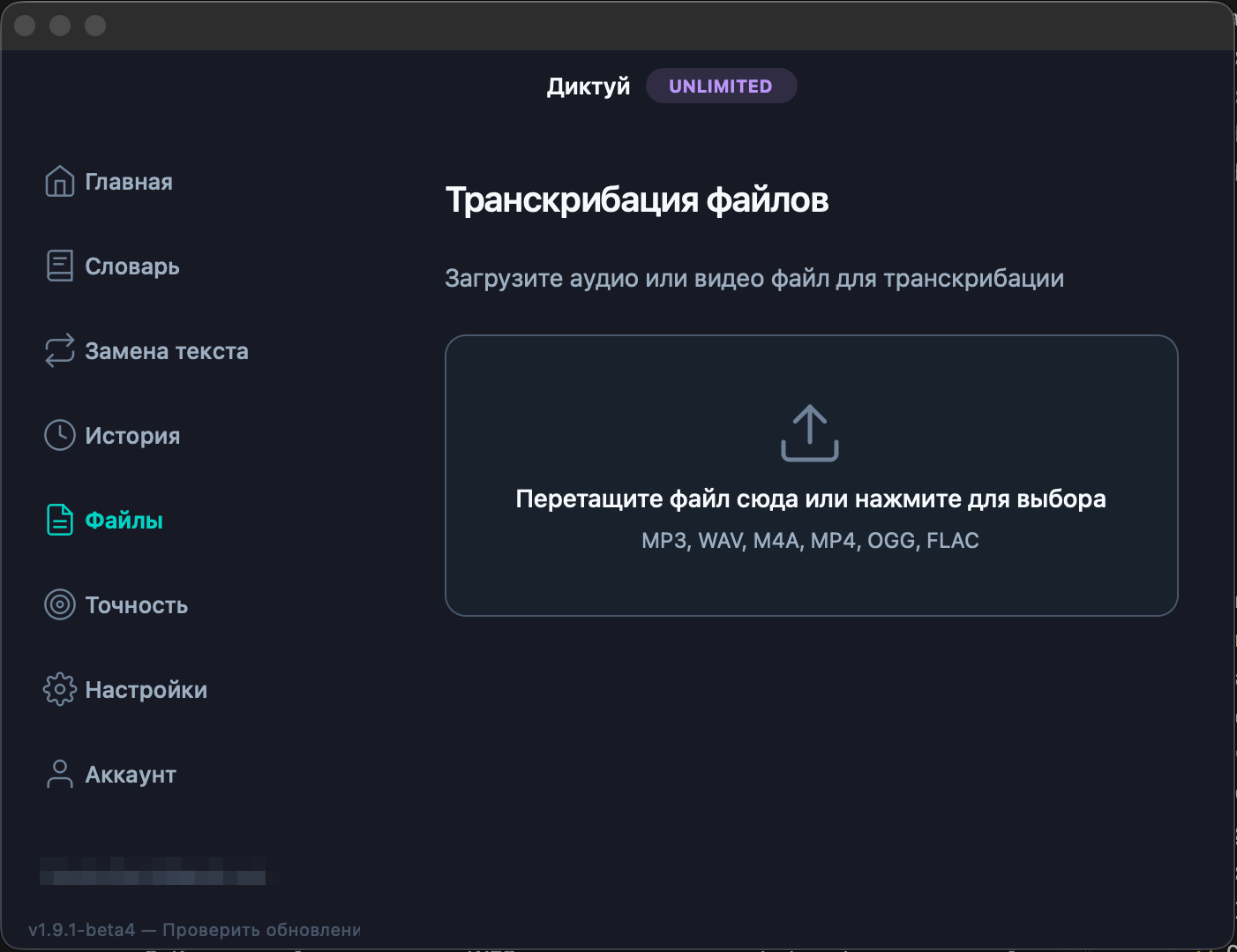
Покажу на конкретном кейсе. Часовое интервью моей знакомой журналистки — M4A с iPhone, 460 МБ, два спикера, чистая запись в тихом кабинете. Открыли Диктуй, переключились на вкладку Транскрибация, перетащили файл. Прогресс-бар появился через секунду.
Что важно понимать про прогресс. Облачные сервисы сначала загружают файл (20-40 секунд для 500 МБ при нормальном интернете), потом ставят в очередь обработки, и только потом распознают. Очередь у Диктуй обычно не загружена — обработка стартует сразу. Через 4 минуты 20 секунд получили готовый .txt.
В сервисах с миллионами пользователей (TurboScribe, Otter.ai) очередь в час пик может быть 5-15 минут. Если работаете в дедлайне — берите подписку с приоритетной очередью, а не free-тариф популярного сервиса.
На выходе ожидаю четыре файла:
- .txt одной простыни — для прочтения и copy-paste
- .docx с заголовком — для отчёта или официальной публикации
- .srt — субтитры со стандартным форматированием для YouTube/Premiere
- Текст с тайм-кодами — для перепрыгивания к моменту в записи
Если сервис экспортирует только .txt без тайм-кодов — он слабый. Для журналистики и юридической работы тайм-коды критичны: цитата без привязки к записи слабее принимается редактором или судьёй.
Точность сырого текста в моей контрольной выборке (100 случайных предложений) — 96.5%. Нашёл 4 ошибки: 2 раза неправильно распознанное имя собеседника, 1 раз «полтора» вместо «полтора миллиона», 1 раз кривая разбивка фразы. Норма для коммерческой записи без специальной подготовки.
Шаг 5. Очистить и оформить расшифровку
Сырая расшифровка ещё не готовый текст. На моём интервью первая страница выглядела примерно так:
Слушай ну вот ты говоришь что у тебя там э-э-э получилось вытащить эту нишу но я ну я не очень понимаю как ты эту нишу нашёл изначально, ну просто потому что в e-commerce это же не очевидно, ну то есть я в смысле не очевидно что вот эта вот ниша...
Чистый Whisper не убирает «э-э-э», «ну», повторы и заминки. Он распознаёт всё подряд — это его задача. Дальше работа уже редактора.
Три рабочих способа очистить:
Вручную. Берёте текст, пробегаете глазами, удаляете лишнее. На часе записи — 30-40 минут. Подходит, когда вы перфекционист и нужен контроль каждого слова. Для журналистики с цитированием — иногда единственный путь.
Через ChatGPT, Claude, Кими, GigaChat или YandexGPT. Копируете блок текста (не больше 5-7 тысяч слов за раз — модели теряют связность на длинных), пишете промпт «убери слова-паразиты, повторы и заминки, сохрани смысл и стиль речи спикера». LLM возвращает причёсанную версию. На часовое интервью — 10-15 минут с проверкой.
Режим трансформации голосом (фича Диктуй, аналог Transforms у Wispr Flow и Rewrite у SuperWhisper). Выделили абзац, нажали хоткей, голосом дали инструкцию: «убери заминки и эээ, оставь живые обороты речи, не формализуй». LLM применяет к выделенному тексту in-place, без переключения окон. Подробно, как пользоваться режимом трансформации в реальной работе с длинными текстами, я разбирал в статье про 30-дневный эксперимент с заменой клавиатуры голосом.
Для часового интервью я использую третий способ. Час разбиваю на 12 равных кусков, каждый прогоняю через трансформацию с инструкцией «убери заминки, оставь авторскую интонацию спикера». Заняло 18 минут вместе с проверкой. Текст где видно человека, не отполированный до состояния пресс-релиза.
Кейсы под конкретные профессии
Под одну и ту же расшифровку у разных пользователей разный финальный артефакт.
Журналист с интервью. Расшифровка → выделение цитат для статьи → подбор к ним тайм-кодов из .srt → отправка эксперту на approval. Ключевая тонкость: журналисту нужны точные слова собеседника, не отполированный пересказ. Поэтому чистка минимальная — убирают только явные «эээ», оставляя стилистические особенности речи. Дополнительно, если интервью на двух людях, без диаризации придётся вручную расставлять «—» по голосам, так что выбор сервиса с разделением спикеров (Sonix, Riverside, Otter) экономит час работы.
Студент с лекцией. Расшифровка → перенос в конспект с собственными комментариями → подсветка ключевых терминов. Для русскоязычной лекции с английскими терминами в IT, медицине или экономике — критичен Whisper, не встроенные ASR (Apple Dictation, Win+H теряют 30-50% точности на mixed RU+EN). Free-тариф 30 минут у Диктуй покрывает 1-2 часовых лекции в месяц без оплаты. Полный workflow от записи пары до готового конспекта — в отдельном гайде «Лекция в текст: как студенту сделать конспект голосом».
Юрист с записью совещания или допроса. Расшифровка → форматирование в таблицу «время — спикер — высказывание» для подшивания к делу. Здесь критична диаризация (нужно показать, кто что сказал) и точные тайм-коды (для перекрёстной проверки с оригиналом записи). Также важен момент — где хранятся данные. Диктуй держит серверы в РФ под 152-ФЗ; зарубежные (Sonix, Otter, TurboScribe) — в США. Для юридически чувствительных материалов первое — соответствие требованиям, второе — иногда блокер. Подробный разбор сценариев под юридическую работу — где облако подходит, где упирается в адвокатскую тайну (ст. 8 ФЗ-63), и почему для адвокатских записей выбирают только локальные модели — в отдельной статье «Голосовой ввод для юристов».
Маркетолог с записью встречи. Расшифровка → AI-саммари (5-7 ключевых пунктов) → отправка по почте участникам. Otter.ai выдаёт саммари автоматически после расшифровки на английском; для русского встреч у меня рабочий шаблон в две минуты — выгрузка текста из Диктуй, потом ChatGPT/Кими промптом «выдели 5 ключевых пунктов и actionable next steps». На часе встречи это сокращает 30 минут на ручное составление протокола.
Программист с голосовыми заметками во время дебага. Архитектурное размышление вслух на прогулке → расшифровка → перенос в Notion или Linear как тикеты. Главная боль здесь — mixed RU+EN: «kubernetes», «postgres», «LangChain», имена методов, аргументов. Apple Dictation и Win+H теряют 30-50% точности на таких терминах; Whisper Large-v3-turbo держит 92-96%. Подробнее как использовать voice в IDE-сценариях — в статье про vibe coding на русском.
Психолог с записью сессии (с письменного согласия клиента). Здесь приватность критична. Единственный совет — локальная модель SuperWhisper на Mac: Whisper работает прямо на устройстве, аудио никуда не отправляется. Облачные сервисы для конфиденциальных сессий не подходят независимо от страны хранения.
Как перевести запись диктофона в текст на iPhone (Voice Memos)
У iPhone-пользователей самый частый сценарий — встроенное приложение Voice Memos (русское название «Диктофон»). Записал лекцию, интервью или голосовое размышление на прогулке — а дальше упирается в то, что встроенной транскрипции в Voice Memos для русского нет. Расшифровка в «Диктофоне» работает на iPhone 12 и новее примерно для десяти языков (английский, основные европейские, японский, корейский, китайский) — русского среди них нет, и на июнь 2026 не появилось. Это не функция Apple Intelligence (она и сама в России без русского), а отдельная встроенная фича — но русскоязычному пользователю в любом случае приходится экспортировать запись наружу.
Формат файла Voice Memos. По умолчанию iPhone пишет в M4A (AAC, 64 kbps моно) — это лёгкий, отлично совместимый со всеми облачными сервисами формат. На iOS 14+ в Настройки → Voice Memos → «Качество звука» → «Без потерь» можно переключить на 24-bit WAV — для интервью с экспертом, где каждое слово критично, это даёт +1-2% точности у Whisper. Но файл становится в 5-7 раз тяжелее.
Где найти файл после записи. Voice Memos хранит запись внутри приложения, не в Файлах. Чтобы достать наружу — открыть запись, кнопка Поделиться (стрелка вверх в углу), варианты:
- AirDrop на Mac — самый быстрый путь, 5 секунд на файл до 1 часа. Получаете .m4a сразу в Загрузках.
- «Сохранить в Файлы» → iCloud Drive — синхронизируется на Windows через iCloud-клиент или web на icloud.com.
- «Сохранить в Файлы» → На моём iPhone — локально, потом достаём кабелем через iTunes/Finder.
- Telegram «Избранное» — отправили сами себе как файл, скачали на ПК. Самый универсальный вариант для русских пользователей без Mac в обиходе.
Как я делаю это сейчас. Voice Memos → Поделиться → Telegram «Избранное» (или AirDrop если запись на Mac рядом) → перетащил .m4a в Диктуй на десктопе → через 1-2 минуты готовая расшифровка с тайм-кодами. Бесплатных 30 минут хватает на 4-5 часовых интервью или 8-10 коротких голосовых на прогулке. После лимита — 299 ₽/мес за 300 минут.
Apple Watch Voice Memos. Часы пишут в формате M4A, потом синхронизируются с Voice Memos на iPhone автоматически (или через 5-10 минут когда iPhone рядом). Дальше тот же путь — поделиться, в облачный сервис, расшифровка.
Совет про Voice Memos для длинных интервью. Если знаете заранее что запись будет на 2+ часа — переключите iPhone в режим «В самолёте» с включённым микрофоном. Никаких уведомлений не дёрнет запись, аккумулятор расходуется медленнее. После записи Wi-Fi включаете и спокойно экспортируете.
Расшифровать прямо на iPhone, без компьютера
Когда компьютера под рукой нет, весь путь делаете на самом телефоне. Облачный сервис на Whisper открывается в Safari или Chrome как обычный сайт: на странице транскрибации кнопка выбора файла открывает «Файлы» iPhone — указываете экспортированный из «Диктофона» M4A, и через одну-две минуты текст готов прямо в браузере. Оттуда копируете в заметки, почту или мессенджер.
Единственное ограничение мобильной загрузки — вес файла. Часовая запись в режиме «Без потерь» легко перевалит за 200 МБ, и по сотовой сети такой файл уходит долго, иногда обрывается на середине. Перед длинной загрузкой включите Wi-Fi, либо держите «Диктофон» в стандартном сжатом M4A (30-50 МБ за час) — точность на нём падает на доли процента, а грузится в разы быстрее.
Короткое голосовое размышление с прогулки расшифровывается вообще без сервиса — через Telegram. Отправляете себе голосовое в «Избранное», под сообщением жмёте кнопку «А» (преобразовать в текст). Русский поддерживается, безлимит идёт в Telegram Premium, бесплатно — несколько штук в неделю. Тонкость: распознаются именно голосовые сообщения, а не аудиофайлы. Запись, лежащая как .m4a из «Диктофона», текстом через Telegram не станет — её всё равно грузят в Whisper-сервис. Как устроена встроенная расшифровка в Telegram, ВКонтакте, WhatsApp и МАКС и где она упирается в лимиты — в разборе «голосовое сообщение в текст».
Android-диктофон в текст: Samsung, Pixel и остальные
На Android единого пути нет — встроенная расшифровка зависит от производителя, и это главная причина, почему запрос «как с диктофона перевести в текст на андроиде» возвращает противоречивые советы.
Samsung Galaxy (One UI 6.1 и новее). Тут повезло владельцам Galaxy: у моделей от линейки S24 встроенный диктофон расшифровывает речь через Galaxy AI — на русском, прямо на устройстве, без интернета и без оплаты. Открываете запись в приложении «Звукозапись», вызываете преобразование в текст, при первом запуске телефон скачивает языковой пакет, дальше распознавание считается локально (плюс к приватности). Для типового сценария Samsung-пользователя — лекция, совещание, голосовая заметка — этого хватает, внешний сервис не нужен.
Google Pixel. Приложение «Запись» (Recorder) русский поддерживает, но с оговоркой: живую расшифровку во время записи русский не держит (там около 15 языков), а вот кнопка «Расшифровать снова» (Transcribe again) прогоняет файл через облако Google и охватывает порядка 42 языков, включая русский. То есть записали, а текст получаете отдельной командой постфактум. Приложение работает только на самих Pixel — на других телефонах его официально нет.
Xiaomi, Huawei, Oppo, realme и прочие. Здесь встроенной русской расшифровки, как правило, нет — диктофон просто пишет звук. Стандартный формат у большинства M4A, у части старых моделей и кастомных приложений — AMR (его перед загрузкой конвертируют в M4A командой из Шага 2). Маршрут такой же, как у iPhone без компьютера: экспортировали запись в «Файлы» или Google Drive, открыли облачный сервис на Whisper в Chrome, загрузили, получили текст. На русском с английскими вкраплениями (частый случай в студенческих и рабочих записях) встроенные ASR любого вендора проседают, а многоязычная модель Whisper держит переключения внутри фразы — почему так устроено технически, разбирал в статье про модель распознавания.
Передать запись с Android без проводов. Быстрее всего без USB-кабеля — отправить файл себе в Telegram «Избранное» или загрузить в Google Drive прямо с телефона, дальше открыть на любом устройстве. А если расшифровываете на том же телефоне, передавать никуда не надо — грузите прямо из «Файлов» в мобильном браузере.
Частые проблемы и как их чинить
AMR-файл не принимается сервисом. Конвертируйте в M4A через ffmpeg: ffmpeg -i recording.amr -c:a aac output.m4a. Эта команда работает на Mac, Windows и Linux одинаково.
Распознавание идёт, но в результате — пустой файл. Скорее всего файл без аудио или с моно-каналом, который сервис интерпретировал как тишину. Проверка: запустить файл в обычном плеере, послушать 30 секунд. Если звук есть только в одном канале — конвертация в моно: ffmpeg -i input.m4a -ac 1 output.m4a.
Точность плохая, хотя запись чистая. Слушайте свою запись не «как звучит для меня», а как услышит машина. Если в фоне музыка или эхо — почистите Audacity (Effects → Noise Reduction) или Adobe Podcast Enhance. Если у спикера сильный акцент — попробуйте сервис со словарём пользователя (в Диктуй это отдельная фича — добавляете специальные термины и имена, и точность на них поднимается после первой пары упоминаний).
Сервис распознал, но криво режет на абзацы. Whisper расставляет тайм-коды, но не всегда понимает где «конец смысловой единицы». Решение в текстовом редакторе (VS Code, Notepad++): поиск-замена \.([А-Я]) → .\n\n$1 — разбивает текст по концу предложения с заглавной буквой.
Два спикера склеились в один поток. Это работа диаризации, которой нет в чистом Whisper. Варианты: переходить на сервис с диаризацией (Sonix, Otter.ai, Riverside) и заплатить чуть больше за фичу; или вручную расставлять «—» по голосам, прослушивая запись. Sonix-диаризация на трёх-четырёх спикерах держит точность 70-85%, что лучше чем 0% у Whisper, но не дотягивает до студийной записи через Riverside, где каждый говорящий пишется на отдельную дорожку с самого начала.
Запись на четыре часа, сервис принимает максимум два. Режьте на части ffmpeg-ом одной командой (см. Шаг 2), грузите кусками, потом склеивайте текст. Альтернатива — Sonix, у которого нет жёсткого лимита по длительности, только по объёму обработанных минут.
Сравнительная таблица: 5 сервисов под диктофонный сценарий
| Сервис | Точность RU | Диаризация | Free-тариф | Цена/мес | Оплата ₽ | Платформы |
|---|---|---|---|---|---|---|
| Диктуй | 95-98% | ❌ | 30 мин | 299-599 ₽ | ✅ МИР, СБП | Win, Mac |
| TurboScribe | 90-94% | ✅ | 30 мин/день | $10-22 | ❌ | Web |
| Riverside | 92-95% | ✅ | trial | $24/мес | ❌ | Web + рекорды |
| Sonix | 92-95% | ✅ | — | $10/час | ❌ | Web |
| Whisper API через Groq | 95-97% | ❌ | бесплатные кредиты | $0.04/час | ❌ | API только |
Краткие выводы: для регулярной работы российскому пользователю выгоднее Диктуй (рублёвая оплата + ИП на УСН с фискальным чеком ОФД + macOS-версия + free 30 минут навсегда). Для длинных интервью с диаризацией разово — Sonix ($10 за час файла). Для студийной записи интервью с привязкой к live-звонку — Riverside ($24/мес). Для шумных записей — Audacity Noise Reduction или Adobe Podcast Enhance перед любым Whisper-сервисом. Для регулярного pipeline у разработчиков с десятками часов в месяц — Whisper API через Groq напрямую.
Полный технический разбор всех восьми сервисов транскрибации с методологией WER-тестирования — в статье про сравнение 8 сервисов. Если ваша задача — расшифровка видеозаписи с YouTube или собственного канала — отдельный пошаговый гайд про транскрибацию видео в текст для блогеров.
Цена ошибки на старте
Самая частая ошибка новичка с диктофонной транскрибацией — взять первый попавшийся бесплатный сервис без проверки на своей записи. Получить точность 70-80% (типично для собственных моделей вроде Otter), потратить три часа на ручную чистку и решить, что «вся эта транскрибация — ерунда».
Реальная разница между топ-3 Whisper-сервисами (Диктуй, TurboScribe, Sonix) и средним рынком — 15-25 пунктов точности. На часе записи это разница между 30-40 минутами лёгкой чистки и тремя часами полного пересказа. Поэтому первый шаг — попробовать Whisper-based решение на free-тарифе, а уже потом решать.
Если регулярно работаете с диктофоном (журналист с 5+ интервью в месяц, юрист с записью допросов, студент с 3+ парами лекций в неделю) — рекомендация прямая: возьмите Диктуй, 30 минут бесплатно, прогоните одну свою запись. Точность должна быть выше 95% на чистой речи. Если ниже — проблема в записи (микрофон, шум, акцент), не в сервисе. Если выше — Pro 299 ₽/мес покроет 5 часов в месяц, что закрывает большинство сценариев одной профессии.
Михаил Воинский — основатель Диктуй. Свой кейс расшифровки записи через Диктуй или другой сервис — пишите на support@diktuy.ru или в @diktuy_help. Подскажу подводные камни на форматах, которые стабильно ломают распознавание.
Часто задаваемые вопросы
В каком формате iPhone сохраняет запись Voice Memos?
По умолчанию iPhone пишет в M4A с кодеком AAC — это совместимый формат, его принимает любой облачный сервис распознавания. С iOS 17+ есть опция Lossless (несжатый WAV) для тех, кому нужна максимальная точность на тихих записях. Из приложения Voice Memos файл экспортируется через кнопку Поделиться → AirDrop на Mac, либо Сохранить в Файлы → iCloud Drive → синхронизация на компьютер. Размер часовой записи в M4A — около 30-50 МБ, помещается в любой облачный лимит.
Что делать с AMR-файлом со старого Android-диктофона?
AMR — устаревший формат низкого битрейта, заточенный под голос для телефонной записи. Часть современных сервисов транскрибации его не принимает. Лечится одной командой ffmpeg: `ffmpeg -i recording.amr -c:a aac output.m4a` — получаете M4A без потери качества речи (AMR изначально содержит меньше информации, чем способен ужать M4A, поэтому качество не падает). После конвертации файл загружается в любой Whisper-сервис стандартным способом.
Можно ли расшифровать Telegram-голосовое в текст?
Да, прямо из мессенджера. Длинное нажатие на голосовое → Сохранить в Файлы (iOS) или экспорт в Drive (Android) — получаете OGG с кодеком Opus. Этот формат напрямую принимают Диктуй, TurboScribe и большинство других облачных сервисов. Точность на голосовых до 5 минут с приличным микрофоном телефона — 92-96% на чистом русском, ниже на mixed RU+EN. Для регулярной работы с Telegram-голосовыми удобно настроить хоткей или интеграцию через Telegram Bot API.
Сколько стоит расшифровка часа записи на диктофоне в 2026?
От 0 до 600 ₽ в зависимости от объёма и сервиса. Бесплатно: 30 минут навсегда у Диктуй (без карты, без trial), 30 минут в день у TurboScribe (валютная карта для апгрейда). Для регулярной работы — подписка с минутами в месяц: Диктуй Pro 299 ₽ за 300 минут (5 часов), Unlimited 599 ₽. По цене за час получается ≈60 ₽ при подписке Pro против $10/час у Sonix или $1-3/мин у живых расшифровщиков. Whisper API через Groq стоит около 4 ₽ за час аудио, но требует кода и собственной обвязки.
Какая точность распознавания диктофонной записи на русском?
На чистой записи (тихая комната, говорящий близко к микрофону, нет наложений) — 95-98% на Whisper Large-v3-turbo. На записи с фоновым шумом (улица, кафе, опен-спейс) — 88-93%. На интервью с двумя собеседниками с похожими голосами — 85-92%, плюс отдельная задача разделить речь по спикерам (диаризация). На профессиональном диктофоне с направленным микрофоном (Zoom H5, Tascam DR-05) точность поднимается ещё на 2-3 пункта против встроенного микрофона телефона.
Можно ли разделить речь на двух говорящих автоматически?
Не все сервисы это умеют. Эта функция называется speaker diarization. На текущий момент диаризацию из готовых десктопных решений делают Sonix, Otter.ai и Riverside. Из российских ASR-моделей с поддержкой диаризации — GigaChat API от Сбера, но это API для разработчиков, без UI. Чистый Whisper диаризацию не делает — он только переводит речь в текст. Для интервью с двумя собеседниками выбирайте сервис с поддержкой нескольких speaker-меток, иначе получите сплошной текст и придётся вручную расставлять «—» по голосам.
Что делать если у диктофона плохой звук — шум, эхо, фоновая музыка?
Сначала почистить аудио, потом расшифровывать. Бесплатно — Audacity (Effects → Noise Reduction): записываете шумовой профиль на участке без речи, применяете ко всему файлу. Платно (1 час бесплатно в месяц) — Adobe Podcast Enhance, веб-инструмент специально под подкастерные записи. Для сильной фоновой музыки — Lalal.ai разделяет дорожки голоса и музыки. После чистки точность распознавания поднимается на 5-15 пунктов на любом Whisper-сервисе. Без предварительной чистки Whisper Large-v3-turbo на сильно зашумлённой записи опускается с 95-98% до 70-80% точности.
Сколько занимает расшифровка часа записи?
От 3 до 7 минут на современных Whisper-сервисах через Groq инфраструктуру (Диктуй, Wispr Flow, SuperWhisper). На Sonix, который запускает Whisper на стандартных GPU — 10-20 минут на час файла. Локальный Whisper на ноутбуке без видеокарты — час-полтора на тот же файл. Поэтому для регулярной работы с диктофонными записями имеет смысл пользоваться cloud-сервисом: разница между 5 минутами и часом обработки накапливается в часы экономии за неделю.
Как перевести запись с диктофона в текст на айфоне?
Встроенный «Диктофон» (Voice Memos) русскую речь не расшифровывает: его транскрипция (iPhone 12 и новее) русский в список не включает, а Apple Intelligence в России не запущен и тоже без русского. Рабочий путь проходится прямо на телефоне — открыть запись, Поделиться, выбрать M4A-файл в мобильном браузере на странице облачного сервиса на Whisper и через одну-две минуты получить текст. Компьютер не нужен. Бесплатных 30 минут у Диктуй хватает протестировать на часовой записи.
Как перевести запись с диктофона в текст на Android?
Зависит от телефона. У Samsung Galaxy с One UI 6.1 и новее (от линейки S24) встроенный диктофон расшифровывает русскую речь прямо на устройстве через Galaxy AI — бесплатно и без интернета. У Google Pixel приложение «Запись» переводит русский только облачной кнопкой «Расшифровать снова». На Xiaomi, Huawei и прочих встроенной русской расшифровки нет — запись грузят в облачный Whisper-сервис из браузера телефона.
Можно ли расшифровать запись диктофона прямо на телефоне, без компьютера?
Да. Любой облачный сервис на Whisper открывается в Safari или Chrome как обычный сайт, кнопка выбора файла даёт доступ к «Файлам» телефона — выбираете M4A или OGG и загружаете без компьютера. Ограничение одно: тяжёлая часовая запись по сотовой сети грузится медленно и может оборваться, поэтому для длинных интервью лучше включить Wi-Fi или оставить запись в сжатом формате.
Расшифровывает ли Telegram голосовые в текст на русском?
Да, русский поддерживается: под голосовым или видеосообщением есть кнопка «А» — преобразовать в текст. Безлимит входит в Telegram Premium, бесплатно доступно несколько расшифровок в неделю. Тонкость: работает это для голосовых сообщений (своих и пересланных), а не для аудиофайлов, отправленных документом — запись с диктофона как .m4a Telegram текстом не сделает, её грузят в Whisper-сервис.