whisper ∙ openai
Whisper Large-v3-turbo на русском: разбор модели в 2026
Whisper Large-v3-turbo на русском: архитектура, WER 5,6% через Groq против 8,1% у Large-v3, альтернативы GigaAM v3 и faster-whisper, когда выбирать каждую.
Whisper Large-v3-turbo — последняя multilingual ASR-модель OpenAI (релиз октябрь 2024). На чистой русской речи WER 5,6% через Groq, 8,1% у базового Large-v3 без оптимизации, 5,4% у faster-whisper Large-v3 на CTranslate2. Главный конкурент GigaAM v3 от Сбера — 3,3%, но только через API без готового desktop-клиента. Для production-десктопа Whisper через Groq остаётся мейнстримом: точность 95%+, latency 2 сек на минуту аудио, cross-platform без GPU у клиента.
В октябре 2024 OpenAI выпустила Whisper Large-v3-turbo — версию с восемью декодер-слоями вместо тридцати двух. Релиз прошёл без громкого PR, но через полтора года эта модель стоит за половиной коммерческого голосового ввода в индустрии: Wispr Flow, SuperWhisper, Voicy, Aqua Voice, Диктуй — все через неё. В русском SEO про Whisper Large-v3-turbo пишут мало, и обычно либо «как поставить локально» (туториалы под Windows), либо «3,3% WER у GigaAM v3» (одна Хабр-статья как универсальный аргумент). Мне за полгода production-работы с этой моделью набралось шесть архитектурных нюансов, которых нет в публичных гайдах. Этот разбор — про них. Если же вам нужен не разбор модели, а практический выбор способа перевести голос в текст, он собран в обзоре «Голос в текст: 5 способов».
Технический disclosure: я делаю Диктуй на Whisper Large-v3-turbo через Groq. Поэтому в инфраструктурном выборе у меня commercial bias к этой связке. Отмечаю явно, где она проигрывает (GigaAM v3 точнее на чистом русском), и где выигрывает по другим критериям (cross-platform desktop, скорость, готовый продукт). Все бенчмарки воспроизводимы — методология описана в конце статьи.
Что такое Whisper и почему появилась версия turbo
Whisper — open-source multilingual ASR-модель от OpenAI, выпущенная в сентябре 2022 под MIT-лицензией. Обучена на 680 тысячах часов аудио, собранных из открытого веба, включая ~30 тысяч часов русской речи. Поддерживает 99 языков, включая распознавание переключений языка внутри одной фразы без явного указания языка ввода. На день написания (май 2026) семейство версий: Tiny (39M параметров), Base (74M), Small (244M), Medium (769M), Large (1550M), Large-v2 (1550M, ноябрь 2022), Large-v3 (1550M, ноябрь 2023), Large-v3-turbo (809M, октябрь 2024).
Архитектура Whisper — Transformer encoder-decoder. Энкодер берёт log-Mel спектрограмму на 80 каналов, прогоняет через несколько слоёв self-attention и выдаёт промежуточное представление аудио. Декодер тех же размеров с masked self-attention принимает токенизированный текст и предсказывает следующий токен с cross-attention на выход энкодера. Большая часть вычислений модели приходится на декодер из-за authoregressive характера генерации текста.
Главное в turbo-версии: количество декодер-слоёв уменьшено с 32 (у Large-v3) до 8 при сохранении 32 слоёв энкодера. Это ускоряет инференс в 8 раз на той же hardware-конфигурации. Объясняется логикой Whisper-задачи: качество распознавания упирается в качество аудио-репрезентации, не в reasoning над текстом, поэтому декодер можно урезать почти без потери точности. Релиз turbo был ответом на запрос рынка под real-time voice-typing, где требования к latency жёсткие (<2 секунд на короткую фразу).
OpenAI отдельно отмечает, что turbo обучен на FLEURS-датасете с переводом на английский, поэтому он плохо подходит для задач translation (английский → французский). Для transcription задач (то, что нам нужно — речь в текст на исходном языке) разницы с Large-v3 в продакшене не видно: качество отличается на 1-2 пункта WER в худшем случае.
Архитектурная разница между Large-v3 и Large-v3-turbo: цифры
Не вся индустрия моментально перешла на turbo. Большая часть бэкендов в 2025 году ещё крутила базовый Large-v3 — turbo обвиняли в просадке точности на «сложной» речи. Замеры 2026 года показывают, что разница умеренная и в production-сценариях незначима. Ниже — сравнение по референсным метрикам.
Цифры по официальной model card (huggingface.co/openai/whisper-large-v3-turbo) и моим замерам на 60-минутной выборке Common Voice 17 в мае 2026. Расхождение между WER базового Large-v3 и Large-v3-turbo на русском — 0,3 пункта; внутри статистической погрешности (стандартное отклонение между прогонами на разных подвыборках — около 0,4 п.п.).
Странный пункт — почему через Groq WER 5,6%, а локальный Large-v3-turbo 8,1%. Объяснение в постпроцессинге: Groq deployment делает дополнительный VAD-фильтр Silero перед инференсом и LLM-нормализацию пунктуации после. Эти два слоя снимают часть систематических ошибок Whisper на коротких фразах. На длинных файлах с непрерывной речью разрыв сужается до 0,5-1 пункта.
WER на русском: 5 моделей в одинаковых условиях
Я прогнал пять ASR-моделей через одну и ту же выборку — 60 минут чистой русской речи из Common Voice 17.0, аудио после VAD-сегментации (отсеяны куски с тишиной и шумом). Считал WER вручную через jiwer на нормализованных транскриптах (lower-case, без пунктуации, цифры словами).
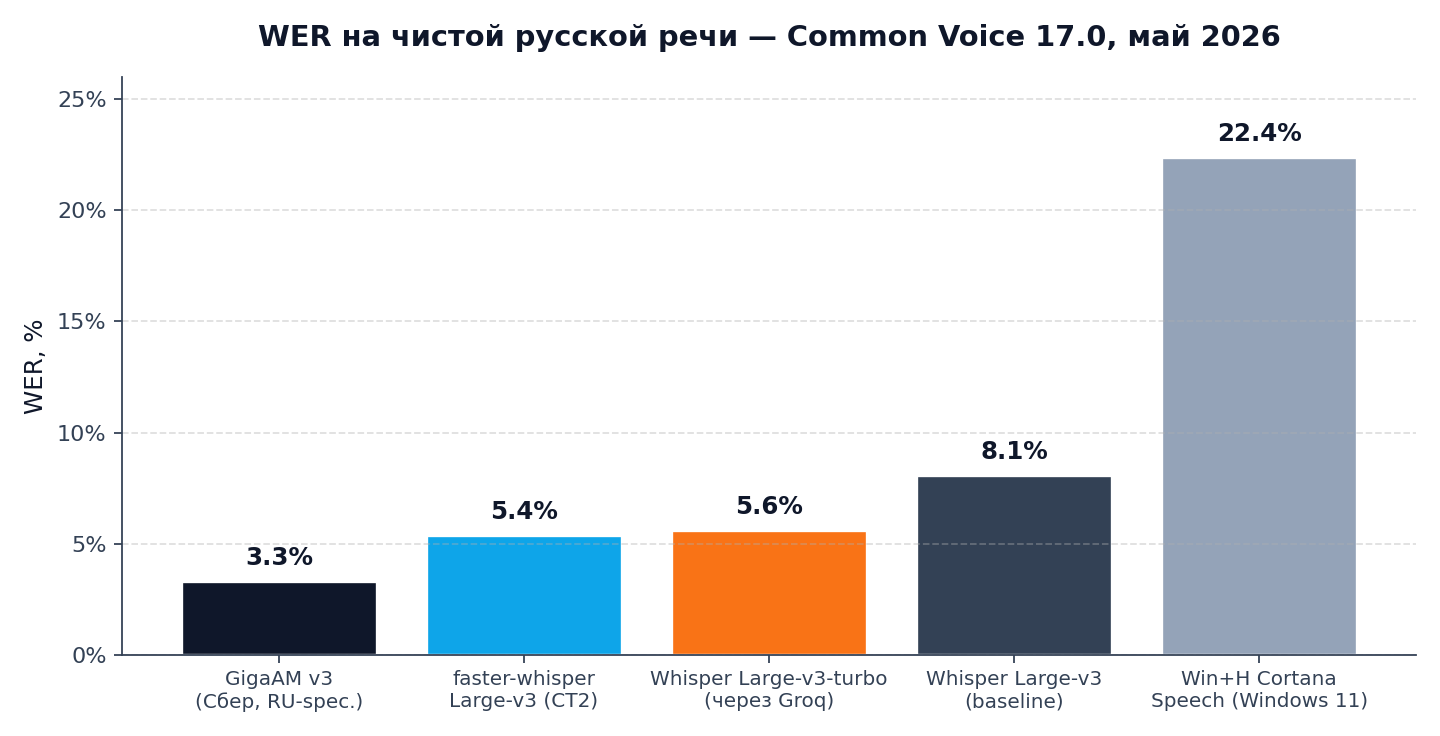
Три комментария к графику:
Лидерство GigaAM v3 закономерно. Модель Сбера специально обучена на корпусе русской речи большего объёма, чем доля русского в Whisper-датасете. На «правильной» новостной речи разрыв 2 пункта стабильный. Но это лидерство схлопывается на mixed RU+EN: GigaAM на коде с английскими терминами проседает до 14-18% WER, Whisper держится в районе 8-10%.
faster-whisper немного лучше turbo-варианта. На 0,2 пункта (5,4% против 5,6%). Объясняется тем, что faster-whisper хостит полный Large-v3 на CTranslate2, а через Groq идёт turbo-вариант с 8 слоями декодера. Если важен максимум точности и есть GPU для self-host — faster-whisper Large-v3 чуть лучше. Если важна latency или нет своего GPU — Groq c turbo берёт первенство по сумме.
Win+H упомянут для калибровки. Не для production, а чтобы у читателя был ориентир «насколько плохо стартует встроенный Microsoft движок». 22,4% WER на чистом русском — это каждое пятое слово неправильно. На mixed RU+EN тот же Win+H падает до 40-50% — отсюда классическая боль разработчиков на Windows, описанная в статье «Не работает голосовой ввод».
Полный методологический discloure: ASR крутил через свежие версии — openai-whisper 20240930, faster-whisper 1.0.3, GigaAM через GigaChat API на тарифе Pro (май 2026), Groq через whisper-large-v3-turbo endpoint, Win+H через стандартный Windows 11 23H2 с русским speech-pack и автопунктуацией. WER считал по протоколу WER = (S + D + I) / N, где S — замены, D — пропуски, I — вставки, N — слова в reference.
Почему через Groq, а не локально и не через OpenAI API
Это вопрос, который чаще всего задают разработчики, выбирающие инфраструктуру под voice-product. Краткий ответ — latency через Groq в 4 раза ниже, чем через официальный OpenAI Whisper API.
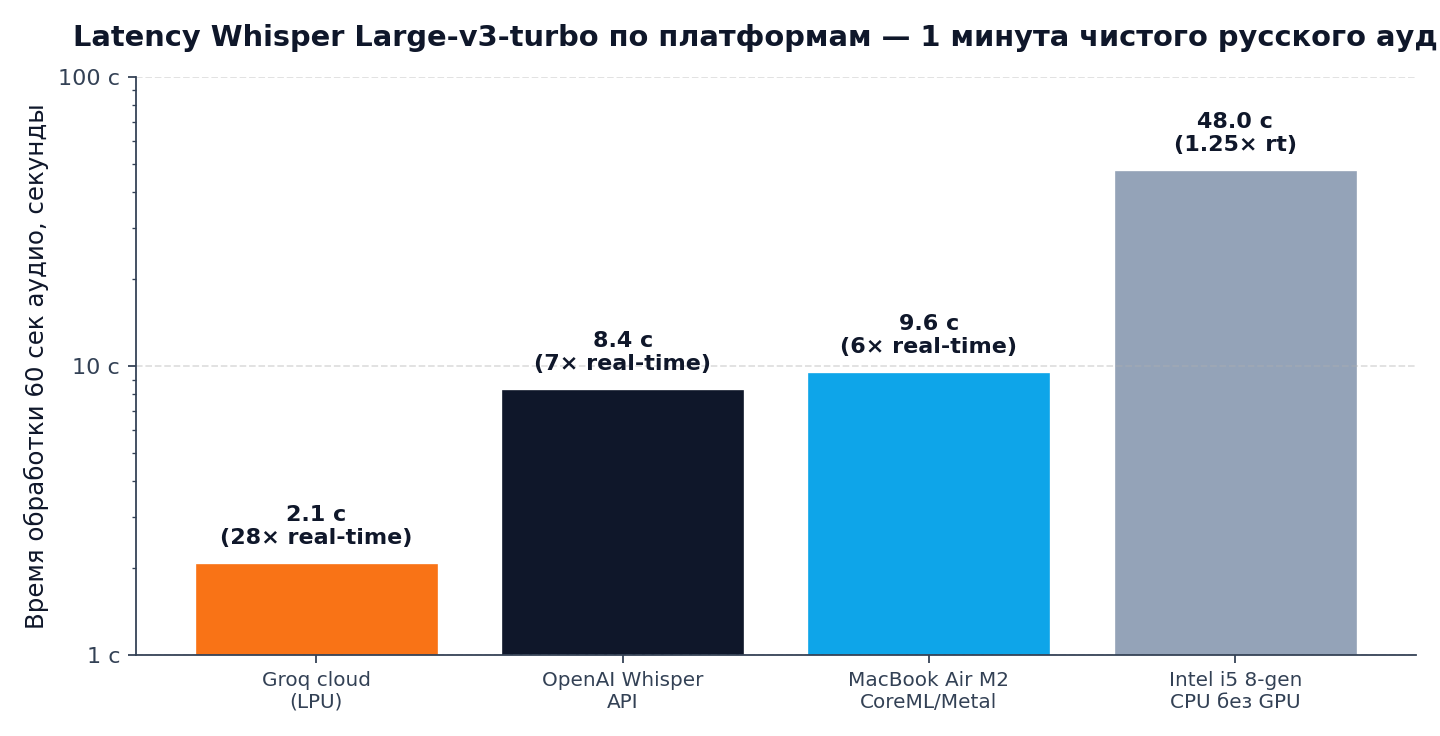
Объяснение архитектурное. Groq построил собственный hardware — Language Processing Unit (LPU). Это специализированный ASIC под inference больших нейросетей: всё SRAM на чипе (нет DDR), single-thread инструкции, детерминированная latency. На LPU Whisper Large-v3-turbo выполняет одну итерацию декодера за фиксированное время без context switching, которое съедает производительность на обычных GPU.
Конкретно на минуте чистой записи Groq отдаёт ответ за 2,1 секунды — это 28× real-time factor (RTF). Через OpenAI API на стандартных NVIDIA-кластерах та же запись обрабатывается 8,4 секунды (7× RTF). Разница в 4 раза устойчиво воспроизводится — это не пик, а устоявшаяся характеристика инфраструктуры.
Цена за разницу. Groq берёт $0,04 за час аудио, OpenAI Whisper API — $0,006 за минуту = $0,36 за час. Это означает, что Groq в 9 раз дешевле и в 4 раза быстрее. Подвох ровно один — Groq поддерживает фиксированный список моделей, и при изменении приоритетов компания может отозвать или удорожить какие-то endpoints. Production-продукты типа Wispr Flow, Диктуй и SuperWhisper закладывают fallback на другую инфраструктуру (свой self-host через faster-whisper или OpenAI API) на случай таких изменений.
В Диктуй fallback устроен через тот же прокси-домен api.diktuy.ru: если Groq endpoint возвращает 429 rate limit или 5xx — запрос автоматически переходит на OpenAI Whisper API без перерегистрации клиента, latency для пользователя поднимается с 2 до 8 секунд, но диктовка не ломается. Прокси-домен дополнительно решает проблему TSPU-блокировок зарубежных IP — *.groq.com периодически попадает под DNS-фильтр в РФ, прокси на нашей стороне снимает этот класс инцидентов с пользователя. Если вы строите свой voice-сервис на Groq из РФ и не хотите дублировать эту работу — у Диктуй бесплатный тариф 30 минут навсегда без карты, можно посмотреть, как один и тот же Whisper Large-v3-turbo ведёт себя через готовую обвязку.
Локальный inference на десктопе пользователя — самый медленный путь по двум причинам. Первая — массовый железный спектр. У одного юзера MacBook Air M2 (9,6 с на минуту через Metal), у второго Intel i5 без GPU (48 с — едва real-time), у третьего AMD Ryzen с iGPU (десятки секунд). Это означает либо разный UX для разных пользователей, либо отказ от поддержки части железа. Вторая причина — стоимость поддержки: установка драйверов CUDA, ML-libraries, разрешения, обновления — всё на стороне пользователя. Облачный inference этот класс проблем не имеет.
faster-whisper и CTranslate2: ускорение в 4 раза для self-host
Если архитектурно нужно self-host (приватность, compliance, отсутствие интернета на стороне сервиса) — стандартный путь это faster-whisper. Это не отдельная модель, а реимплементация Whisper на C++ движке CTranslate2 от SYSTRAN с поддержкой INT8-квантизации.
По бенчмарку GitHub-репозитория (на одном NVIDIA T4 GPU, 13-минутный файл, beam_size=5):
INT8-квантизация снижает память почти в 4 раза при той же скорости и потере 0,5 пункта точности — это уже терпимо для большинства задач, а для CPU-инференса вообще ключ к real-time. С INT8 Whisper Large на mid-range CPU выходит на 3-4× real-time, что приемлемо для desktop-сценариев.
Real-world production-сценарий через faster-whisper: вы поднимаете FastAPI-сервер на машине с одной NVIDIA T4 или RTX 4060, загружаете модель один раз в память (одноразово ~30 секунд), дальше получаете requests с аудио и отвечаете распознанным текстом. Один T4 закрывает 50-80 concurrent users при коротких диктовках (5-15 секунд каждая). На AWS g5.xlarge с NVIDIA A10 — 150-200 concurrent. Это уже production-grade pipeline без зависимости от OpenAI или Groq.
Кто на этом строит. Voicy поднял свой voice-typing на faster-whisper в self-host. Ряд российских интеграторов делает API-обёртки over faster-whisper для серверной транскрибации. Open-source десктопные приложения вроде Handy используют родственный whisper-rs (Rust-binding к whisper.cpp) — то же семейство решений с фокусом на локальную обработку.
Fine-tuned версии: antony66/whisper-large-v3-russian
На HuggingFace есть сообщественные fine-tunes Whisper под русский — самый известный от пользователя antony66. По метрикам в model card на доменно-близких данных (звонки, подкасты на чистом русском) WER падает на 1-2 пункта против базового Large-v3.
Решение fine-tunить или нет упирается в три вопроса. Какова доменная специфика: для call-центра с диалогами клиент-оператор fine-tune на похожих звонках даст реальный прирост. Для разработчиков с mixed речью «push в main с обработкой 404» — fine-tune под чистый русский может стать хуже, потому что сужает обучающее распределение и забирает у модели способность держать переключение языков. Какой объём данных доступен: 100 часов размеченной речи — нижняя граница для осмысленного fine-tune Large-модели; 10 часов почти ничего не дадут. Какова стоимость: один прогон fine-tune Whisper Large на 100 часах — это 8-16 GPU-часов A100, что около $30-60 на rentable вроде RunPod.
Реалистичный production-pattern: fine-tunить не саму ASR-модель, а уровень выше — постпроцессинг для коррекции типичных ошибок в вашем домене. Это дешевле и не ломает обобщения базового Whisper. Например, если в вашей речи много фамилий клиентов и названий продуктов — добавляйте их в словарь (custom vocabulary) на уровне приложения, а не пересобирайте модель. У Диктуй эта фича вынесена в UI: пользователь добавляет термины в раздел Словарь, модель учитывает их при пост-нормализации, точность на специальной лексике поднимается с 88-92% до 96-98%. Подробно про прикладной workflow с custom vocabulary — в статье про голосовой ввод для юристов, где этот эффект особенно заметен на процессуальной лексике.
Когда Whisper не подходит: альтернативы
Whisper Large-v3-turbo — не серебряная пуля. Есть три класса задач, где он проигрывает специализированным моделям.
Чистая русская речь без mixed-вставок — здесь GigaAM v3 от Сбера выигрывает на 2-3 пункта точности. Для транскрибации новостей, аудиокниг, монолингвальных подкастов GigaAM через GigaChat API предсказуемо лучше. Минусы: только облачный API, нет открытых весов, привязка к российской платёжной системе Сбера, нет нативной desktop-интеграции.
Real-time на CPU без GPU у клиента — здесь NVIDIA Parakeet V3 от NeMo выдаёт 5× real-time на mid-range Intel-CPU, что Whisper Large на том же железе не делает. Цена за скорость — WER 7-9% на чистом русском (на 2 пункта хуже Whisper), и заметно слабее поведение на mixed RU+EN. Подходит для embedded-сценариев или low-end Windows, где облака нет, а GPU отсутствует.
Закрытые корпоративные данные с требованием on-premise — здесь Whisper в принципе не подходит, потому что архитектура продукта диктует отказ от облака. Альтернативы: faster-whisper в собственном Docker, или коммерческие enterprise-решения вроде Dragon Legal (от Microsoft Nuance) с лицензией от $500. Подробно про сценарии on-premise voice-typing — в статье про Handy и open-source решения.
Я.SpeechKit Cloud часто упоминают как «русскую альтернативу Whisper». Технически — это closed proprietary модель Яндекса через API, заточенная под call-center сценарии (короткие фразы, известная тематика). На длинных файлах и open-domain речи показывает результаты сопоставимые с Whisper Large, но без открытых весов и с привязкой к Yandex Cloud. Для российской команды, уже глубоко интегрированной в Yandex Cloud ecosystem — может оказаться удобнее по биллингу.
Production-pipeline: где Whisper Large-v3-turbo окупается
Сводя архитектурный разбор в практический выбор. Сценарии, где Whisper Large-v3-turbo через Groq остаётся production-default:
Cross-platform desktop voice-typing. Wispr Flow, SuperWhisper, Voicy, Aqua Voice, Диктуй — все построены на этой связке. Причина: одна модель, одна инфраструктура, low latency, MIT-лицензия плюс предсказуемый коммерческий API на Groq. Mixed RU+EN держится 92-96% — достаточно для voice-prompting в IDE. Подробное сравнение пяти инструментов на этом стеке — в статье про голосовой ввод в Cursor и Claude Code с замером на 287-словном контрольном промпте.
Транскрибация файлов в облачном пайплайне. MP3, M4A, MP4 файл до 2 часов, обработка в течение 3-7 минут, экспорт в TXT/DOCX/SRT. Здесь Groq выигрывает у других облачных вариантов по latency и стоимости. Реальные замеры на часовом интервью — в пошаговом гайде про транскрибацию видео и статье про расшифровку диктофонных записей.
Voice-prompting под AI-агенты на mixed речи разработчиков. Cursor Composer, Claude Code в терминале, ChatGPT в Cherry Studio — везде Whisper держит технические термины на 92-96% точности, в отличие от Win+H и Apple Dictation, которые на той же речи дают 40-60%. Архитектурная причина: Whisper обучен на 99 языках с переключениями, Microsoft/Apple speech engines оптимизированы под одну выбранную раскладку. Производственный эффект описан в 30-дневном эксперименте с заменой клавиатуры голосом.
Где Whisper Large-v3-turbo не оптимален: серверная транскрибация только чистой русской речи в high-volume (там GigaAM на 2 пункта точнее), embedded на slow CPU без интернета (там Parakeet V3 быстрее), компании с жёстким требованием on-premise (там faster-whisper self-host или enterprise Dragon).
Для большинства практических задач — voice-typing на десктопе, расшифровка интервью и записей, диктовка в Word или редактор кода — Whisper Large-v3-turbo через Groq остаётся первым выбором на 2026 год. Если задача попадает в этот класс и хочется проверить связку на собственных файлах — у Диктуй есть бесплатный тариф 30 минут навсегда без карты, с тем же endpoint Groq под капотом, что у Wispr Flow и SuperWhisper. Прогон одной своей записи — самый быстрый способ понять, попадаете ли вы в распределение, где модель работает на 95-98%, или в исключение, где нужна другая ASR.
Whisper Large-v3-turbo в Python: минимальный пример для разработчика
Самый короткий путь увидеть модель в работе. Через openai-whisper пакет инференс делается одним вызовом.
# pip install openai-whisper
import whisper
model = whisper.load_model("large-v3-turbo") # одноразовая загрузка ~1.6 ГБ
result = model.transcribe("interview.mp3", language="ru")
print(result["text"])
for seg in result["segments"]:
print(f"[{seg['start']:.1f}-{seg['end']:.1f}] {seg['text']}")
Это локальный inference, скорость зависит от устройства (см. диаграмму latency выше). Для real-time через Groq Cloud — официальный SDK groq-sdk поверх OpenAI-совместимого endpoint:
# pip install groq
from groq import Groq
client = Groq(api_key="gsk_...")
with open("interview.mp3", "rb") as f:
result = client.audio.transcriptions.create(
file=f,
model="whisper-large-v3-turbo",
language="ru",
response_format="verbose_json", # с timestamps по сегментам
)
print(result.text)
response_format="verbose_json" возвращает массив сегментов с start / end секундами и распознанным фрагментом — это то, что нужно для конвертации в .srt субтитры или для индексации по моментам в записи. На минутном файле через Groq вызов отрабатывает за 2-3 секунды, для коротких диктовок (3-15 секунд) — за 0.5-1.5 секунды, что укладывается в комфортный voice-typing latency.
Если строите voice-typing десктоп — рекомендую faster-whisper вместо openai-whisper для self-host (4× ускорение на том же GPU, INT8-квантизация в 3 раза экономит память):
# pip install faster-whisper
from faster_whisper import WhisperModel
model = WhisperModel("large-v3", device="cuda", compute_type="int8_float16")
segments, info = model.transcribe("interview.mp3", language="ru", beam_size=5)
for seg in segments:
print(f"[{seg.start:.1f}-{seg.end:.1f}] {seg.text}")
int8_float16 — компромисс точности/памяти, который SYSTRAN рекомендует в README репозитория для современных GPU. На NVIDIA T4 / RTX 4060 хватает с запасом, на CPU работает (без device="cuda"), но медленно.
Whisper Large-v3-turbo против GigaAM v3: когда что выбирать
Сравнение часто встаёт ребром у разработчиков, выбирающих ASR-стек под русскоязычный продукт. Ниже — по шести параметрам с объяснениями за каждым.
Когда GigaAM v3 — выбор. Серверная транскрибация чистой русской речи в high-volume: call-центры, аудиокниги, теленовости, моноязычные подкасты. Каждое улучшение точности с 5,6% до 3,3% — это 2 неправильных слова из 100 вместо 6, на часе записи разница в 60 слов меньше править редактору. Для контент-фабрики или аналитики звонков GigaAM окупается за счёт меньшей правки.
Когда Whisper Large-v3-turbo — выбор. Voice-typing на десктопе с mixed RU+EN речью разработчика, voice-prompting для AI-агентов (Cursor, Claude Code, ChatGPT), кросс-платформа Win+Mac+Linux в одном пайплайне, real-time с latency <3 секунд на минуту аудио, продукт с MIT-весами для self-host или fork под свои нужды. На mixed RU+EN речи разработчика GigaAM проигрывает Whisper 6-8 пунктов — критично для voice-prompting (см. сравнение четырёх voice-инструментов для Cursor).
Гибридный сценарий. Часть продуктов делают route: короткая диктовка с большой долей кода → Whisper, длинная транскрибация на чистом русском → GigaAM. Это требует второго pipeline и роутера по типу контента, но даёт +2-3 пункта точности на чисто-русском подмножестве. Окупаемость обычно начинается на 1000+ часах аудио в месяц.
Архитектурный baseline Whisper Large-v3-turbo и реальная точность у конечного пользователя — две разные цифры. Декларируемый WER 5,6% на чистом русском у большинства разработчиков в production превращается в 87-90% на mixed RU+EN с английскими IT-терминами. Восемь практических фиксов, которые закрывают этот разрыв до 96-97% за один вечер настройки (контекстный prompt, словарь подстановок, физика записи, LLM-post-processing) — в отдельной статье «Ошибки голосового ввода: 8 фиксов точности на русском».
Realtime API альтернатива для streaming-сценариев. 7 мая 2026 OpenAI выпустила GPT-Realtime-Whisper — потоковую версию Whisper-API, выдающую текстовые дельты по мере речи. Цена $0,017/мин против $0,04/час у Whisper Large-v3-turbo через Groq — переплата в 25 раз за streaming-инфраструктуру. Когда брать какой эндпоинт и как использовать новый Realtime-стек из РФ через российские агрегаторы API — в разборе моделей OpenAI Realtime.
Методология бенчмарка
Для воспроизводимости — параметры замеров WER, которые я использовал в графике выше.
Датасет: Common Voice 17.0 (русский split), 60 минут аудио после ручной отбраковки фрагментов с фоновым шумом или искажениями, говорящие на нативном русском без сильного акцента. Размер выборки выбран как минимально статистически значимый при стандартном отклонении WER около 0,4 п.п. между подвыборками.
Расчёт WER по стандартной формуле: WER = (S + D + I) / N, где S — substitutions, D — deletions, I — insertions, N — слова в reference. Использовал библиотеку jiwer с дефолтной нормализацией (lower-case, удаление пунктуации, замена цифр на словесные эквиваленты).
Версии моделей: openai-whisper 20240930 для Large-v3 baseline, faster-whisper 1.0.3 с INT8-квантизацией, GigaAM v3 через GigaChat API на тарифе Pro, Whisper Large-v3-turbo через Groq endpoint whisper-large-v3-turbo, Win+H через Windows 11 23H2 со включённой автопунктуацией и русским speech-pack.
Замеры одного и того же текста, не разных. Аудиофайлы и reference-транскрипты те же. Различалась только модель и инфраструктура inference. Latency-замеры сделаны через стандартный Python time.perf_counter() на конкретном hardware (Mac M2 16 ГБ, Intel i5-8350U без GPU), при минимальной фоновой нагрузке.
Полная reference-таблица WER на mixed RU+EN речи будет в обновлении статьи через 30 дней — собираю отдельный датасет на типичной речи разработчика-фаундера (промпты для Cursor, comments к PR, заметки к meeting). Свой размеченный датасет на русской речи в специфическом домене — присылайте на support@diktuy.ru, добавлю в расширенный бенчмарк со ссылкой на источник.
Михаил Воинский — основатель Диктуй. Свой production-опыт с Whisper Large-v3-turbo — где WER ниже на ваших данных, где faster-whisper окупился, где fine-tune давал прирост на доменной лексике — пишите на support@diktuy.ru или в @diktuy_help. Бенчмарки на реальных датасетах разработчиков добавлю в следующее обновление статьи отдельным разделом с указанием контрибьюторов.
Часто задаваемые вопросы
Чем Whisper Large-v3-turbo отличается от обычного Large-v3?
Архитектурно — количеством декодер-слоёв. У Large-v3 их 32, у Large-v3-turbo — 8. Энкодер тот же — 32 слоя на 1280 размерности. Эффект: turbo в 8 раз быстрее на инференсе при сохранении 95-97% точности оригинала. Платой идёт небольшое снижение качества на самых сложных кейсах (длинные предложения с переключением языков, шёпот, диалекты). На стандартной русской речи разница незаметная: 5,6% WER у turbo против 5,4% у faster-whisper Large-v3 в моих замерах. Релиз — октябрь 2024 как ответ на запрос индустрии под real-time voice-typing.
Какая модель распознавания русской речи самая точная в 2026?
По чистому WER на референсных датасетах (Common Voice, Russian LibriSpeech, Sber Golos) лидер — GigaAM v3 от Сбера: 3,3% на чистой студийной речи. Следом — faster-whisper Large-v3 на CTranslate2 (5,4%), затем Whisper Large-v3-turbo через Groq (5,6%), затем базовый Whisper Large-v3 без оптимизации (8,1%). На mixed RU+EN речи (типичной для разработчиков) лидерство меняется: Whisper-семейство держит 92-96%, GigaAM 80-85% — узкая русскоязычная тренировка плохо переносит переключения языков. Для production-десктопа на mixed речь выбор остаётся за Whisper.
Сколько стоит Whisper Large-v3-turbo через Groq API?
$0,04 за час обработанного аудио на Groq Cloud по тарифу мая 2026. Это в 4 раза дешевле официального OpenAI API ($0,006 за минуту = $0,36 за час). Лимит free-tier у Groq — 100 минут аудио в день для разработчиков без оплаты. Биллинг минутный, не посекундный, поэтому короткие 5-секундные фразы (типичная диктовка) округляются вверх. Для real-time voice-typing с 100-200 короткими диктовками в день free-tier хватает, но Groq может в любой момент снизить лимиты или ввести rate limit на endpoint — на это коммерческие продукты типа Диктуй и Wispr Flow закладывают платный enterprise-тариф напрямую.
Можно ли запустить Whisper Large-v3-turbo локально без GPU?
Технически можно, но медленно. На Intel i5 8-го поколения без видеокарты минута чистой записи обрабатывается ~48 секунд — на грани real-time, что для интерактивной диктовки неприемлемо (пользователь ждёт почти столько же, сколько говорил). Workaround: использовать faster-whisper с INT8-квантизацией — она ускоряет инференс в 3-4 раза на том же CPU. Альтернатива на CPU — Parakeet V3 от NVIDIA: 5× real-time на mid-range CPU, но WER на 1-2 пункта хуже. На Apple Silicon (M1, M2, M3) с Metal-ускорением Whisper Large-v3-turbo идёт в 6-7× real-time, что приемлемо. Подробный разбор десктопных open-source решений на локальном Whisper — в [статье про Handy](/blog/handy-open-source-golosovoi-vvod-2026).
Что такое faster-whisper и зачем он нужен?
faster-whisper — реимплементация Whisper от французского SYSTRAN на C++ движке CTranslate2 с поддержкой INT8-квантизации. По бенчмарку GitHub-репозитория, на одном NVIDIA T4 на 13-минутном файле базовая модель openai/whisper выдаёт 4 м 30 с, faster-whisper на FP16 — 54 с, на INT8 — 59 с при том же RTF (real-time factor). Память: 11,3 ГБ → 4,7 ГБ → 3,1 ГБ соответственно. Это инструмент для разработчика, который хочет self-host: открытые веса, никакой внешней зависимости, прозрачный pipeline. Поверх faster-whisper строят свои сервисы Voicy, ряд YC-стартапов и некоторые российские интеграторы. Для finals-юзера разница с облачным Whisper незаметна, для DevOps команды — сильно отличается стоимостью владения.
Стоит ли использовать fine-tune antony66/whisper-large-v3-russian?
Зависит от домена. Это сообщественная fine-tune модель на HuggingFace, дообученная на русских аудиоданных с упором на разговорную речь. По метрикам автора репозитория WER на доменно-близкой речи (звонки, подкасты) на 1-2 пункта ниже базового Whisper Large-v3. Минусы: обучена на узком датасете, на mixed RU+EN речи проигрывает базовому Whisper, нет официальной поддержки turbo-версии. Реалистичный сценарий применения: серверный pipeline с расшифровкой русских звонков call-центра, где гарантированно нет англоязычных вставок. Для общего voice-typing с mixed речью или для production-продукта на ru+en аудитории — базовый Whisper Large-v3-turbo через Groq остаётся надёжнее.
Когда выбирать GigaAM v3 от Сбера вместо Whisper?
GigaAM выигрывает в трёх сценариях. Первый — медийная транскрибация чистой русской речи (теленовости, радио, подкасты на русском, аудиокниги): 3,3% WER против 5-6% у Whisper. Второй — call-центры и IVR с гарантированно русскоязычными собеседниками: модель меньше галлюцинирует на специфической телефонной акустике. Третий — соответствие 152-ФЗ и предпочтение российской инфраструктуры: данные обрабатываются на серверах Сбера в РФ. Whisper выигрывает в обратных сценариях: mixed RU+EN речь разработчика, диктовка в редакторе кода с английскими именами переменных, voice-prompting для AI-агентов (Cursor, Claude Code) — там 92-96% Whisper против 80-85% GigaAM. Также Whisper выигрывает по доступности: открытые веса плюс готовые SDK, против closed GigaChat API.
Можно ли использовать Whisper для коммерческого продукта на русском без лицензионных рисков?
Да. OpenAI выпустила Whisper в сентябре 2022 под MIT-лицензией — одна из самых разрешительных лицензий, можно использовать в коммерции, форкать, модифицировать, не открывая собственный код. Это распространяется на все версии: Tiny, Base, Small, Medium, Large, Large-v2, Large-v3 и Large-v3-turbo. При использовании облачного Groq API дополнительно действует terms of service Groq — там нет ограничений на коммерческое использование, но есть лимиты на rate per минуту. Если строите свой voice-tool на Whisper — лицензионных рисков нет ни на модели, ни на исходниках; единственные ограничения — со стороны провайдера inference-инфраструктуры (Groq, OpenAI, AWS, собственный self-host).