troubleshooting ∙ точность
Ошибки голосового ввода: 8 фиксов точности на русском в 2026
Голосовой ввод путает термины, имена и mixed RU+EN? 8 причин почему точность падает до 87% и как поднять до 97% через словарь и контекстный prompt.
Whisper Large-v3-turbo на чистом русском без специальной лексики даёт 95–98% точности — у большинства в реальной работе 85–90%. Эти 5–10 пунктов теряются на 8 типичных причинах: микрофон и расстояние, шумная комната, скорость речи, отсутствие контекстного prompt, незаполненный словарь подстановок, переключения RU+EN, цифры и единицы, пропущенный post-processing AI. Каждая чинится отдельно за 10–30 минут, менять сервис или модель не нужно.
Откуда берётся разрыв между 95% и 87%
Точность Whisper Large-v3-turbo на чистом русском без специальной лексики — 95–98% по бенчмарку OpenAI и собственному WER-тесту нашей команды на корпусе разговорной речи. У большинства пользователей в реальной работе — 85–90%. Разница в 5–10 пунктов точности — это разница между «текст сразу в дело» и «пять минут чистить грамматику после каждого абзаца». Эти 5–10 пунктов почти всегда теряются на восьми типичных причинах, и ни одна из них не требует менять сервис или модель. А если вы только выбираете, каким способом вообще переводить голос в текст, начните с обзора «Голос в текст: 5 способов» — там разложены все маршруты от живой диктовки до Whisper API.
Я веду Диктуй два года, и из 1 200+ обращений в поддержку про точность примерно 85% решается одним из восьми фиксов ниже. Остальные 15% — это или объективные пределы (диаризация говорящих, точная орфография длинных латинских цитат), или fundamentals не на стороне сервиса (плохая запись, сильный акцент, фоновая музыка). Этот гайд — про восемь чинимых причин.
Технический disclosure: я делаю Диктуй — российский voice-typing сервис на Whisper Large-v3-turbo. Один из инструментов в этой статье — словарь подстановок Диктуй, которым я пользуюсь сам каждый день для имён коллег, IT-терминов и редких русских фамилий. Подачу намеренно сделал product-agnostic: шесть из восьми фиксов работают в любом voice-tool на Whisper-модели (SuperWhisper, Wispr, Handy, faster-whisper), не только в Диктуй. Где Диктуй упомянут — там приведён эквивалент в других сервисах.
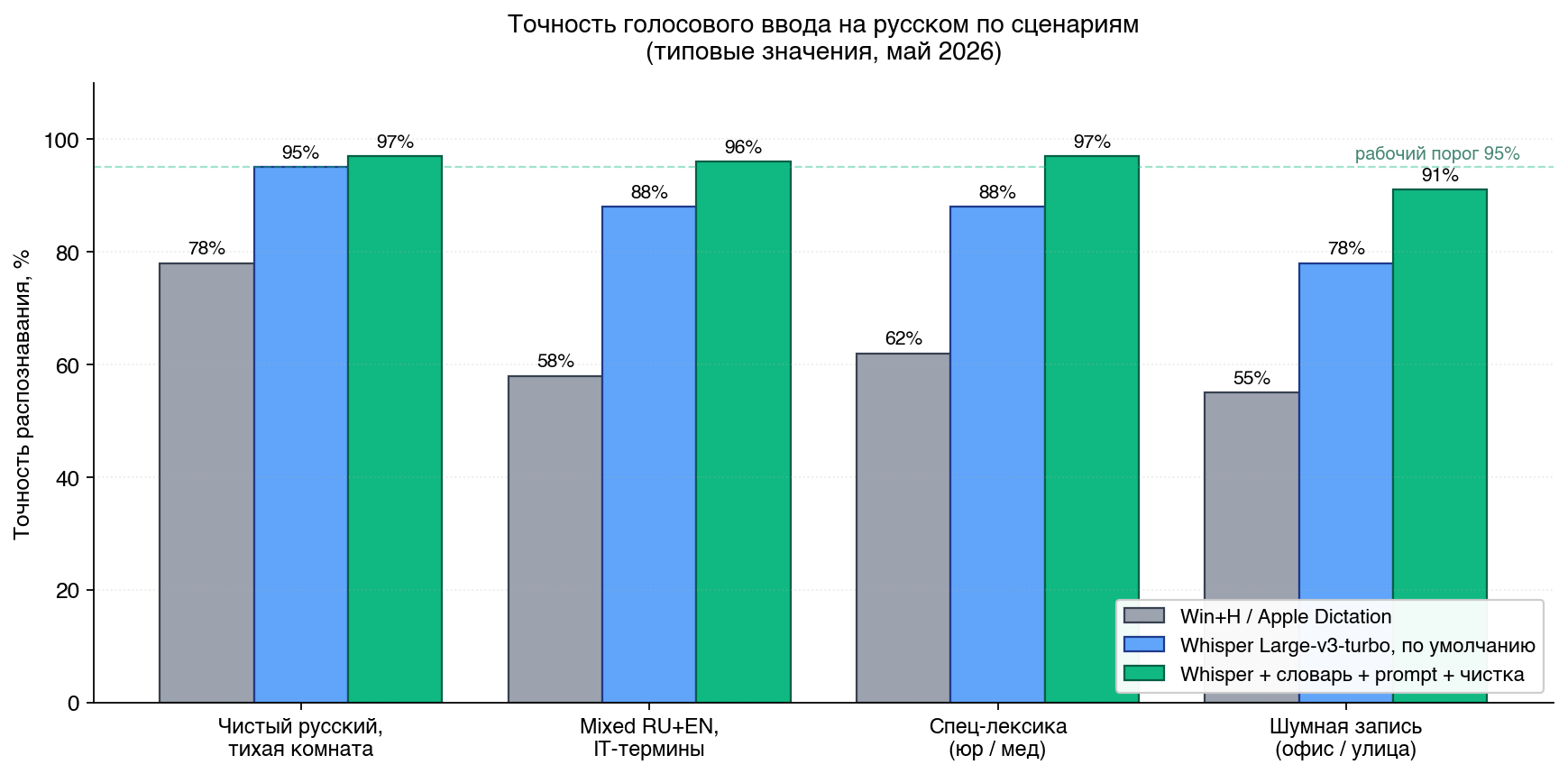
Цифры на диаграмме — типовые значения из наших тестов и публичных бенчмарков (OpenAI Whisper paper, Habr-разбор Wispr Flow / Handy / OpenWhispr / GigaAM от @egorsokolov). Точные WER на ваших данных могут отличаться, но порядок и пропорции выдерживаются.
Сначала проверьте: воспроизводится ли проблема
Перед любыми правками нужна базовая линия. Иначе после изменения настроек непонятно, что именно сработало, а что нет.
Минимальный набор для замера — записать одну и ту же тестовую фразу через voice-tool, посчитать ошибки.
Тестовая фраза 287 знаков из реальной IT-диктовки: «Давай задеплоим этот endpoint через GitHub Actions с переменной DATABASE_URL, проверим что Postgres мигрировал, и накатим миграцию для customer_id. Кубернетес ingress-controller должен пересоздаться сам через rolling update, но если нет — перезапусти deployment вручную через kubectl apply».
Прогнать эту фразу в одном проходе через ваш voice-tool, посчитать число ошибочно распознанных слов (включая склеенные «kubernetes» в «куб ернетес», подменённые «endpoint» на «end point», пропавшие «ingress-controller»). Если ошибок 6+ на 45 слов — у вас классический mixed RU+EN провал, который чинится фиксами 4–6 ниже.
Если ваш сценарий не IT, замените эту фразу на типовое предложение из вашей рабочей лексики (юристу — про обременение и правопреемство; врачу — про дифференциальный диагноз и фармакокинетику; маркетологу — про CPC и ROAS на CTR).
Фикс 1. Микрофон и расстояние ото рта
Самая частая причина потери точности — не модель, а физика записи. Встроенный микрофон ноутбука на расстоянии 50 см от рта ловит до 8–12 пунктов точности меньше, чем USB-гарнитура с направленным микрофоном в 10–15 см ото рта.
Проверка: записать 30 секунд тестовой речи в Audacity или QuickTime, посмотреть на уровень громкости. Пиковые значения должны быть в диапазоне -12 дБ до -6 дБ — это «жирная» речь, которую модель распознает уверенно. Уровень -25 дБ и ниже = громкость накручивается в драйвере, фоновый шум подтягивается с ней, точность падает.
Решение: USB-гарнитура за 1 500–3 000 ₽ (Logitech H540, Defender Gryphon 750U, Trust Mauro). Не нужны конденсаторные микрофоны Blue Yeti / Rode NT-USB — они ловят больше шума окружения, не лучше для voice typing. Прирост на mixed RU+EN тесте — 4–8 пунктов точности сразу, без других правок.
Фикс 2. Шумная среда и реверберация
Кондиционер, открытое окно с улицей и резонанс пустой комнаты роняют точность на 7–15 пунктов. Whisper пытается распознать шум как речь и иногда «угадывает» слова, которых не было.
Проверка: записать 30 секунд молчания, послушать через наушники. Слышен ровный гул кондиционера, низкочастотный шум вентилятора, эхо от голых стен — это попадает в распознавание.
Решение бесплатное: занавес на окно, плед на стол, ковёр на пол — простейший акустический treatment роняет реверберацию вдвое. Кондиционер выключить на время диктовки. Если рядом холодильник или сервер — диктовать в наушниках с активным шумоподавлением, микрофон ближе ко рту.
Решение для диктофонных записей: Adobe Podcast Enhance — 1 час бесплатно в месяц, специально под подкастерные/диктофонные записи. После Enhance точность Whisper на шумной записи поднимается с 75–80% до 90–93%.
Фикс 3. Скорость речи и артикуляция
Whisper обучен на разговорной речи в темпе 130–150 слов в минуту. Когда вы говорите 180–200 слов в минуту (типичный темп нервного пересказа или презентации), модель пропускает окончания и склеивает короткие слова: «давай-ка» в «давайка», «то есть» в «тоесть», «как-то» в «както».
Проверка: засеките минуту обычной диктовки, посчитайте слова в результате. Норма для качественного распознавания — 130–150. Темп 170+ — у вас будут систематические проседания на окончаниях.
Решение: говорить как будто диктуете секретарю. Пауза перед каждой фразой 0.3 секунды, отчётливое окончание гласных, не глотать предлоги. Звучит странно первые 15 минут, через час привыкаешь. Прирост 2–4 пункта точности на длинных предложениях.
Дополнительная польза: замедленный темп уменьшает усталость голосовых связок при длинных сессиях. За 2-часовую диктовку в темпе 200 слов в минуту связки звереют, в темпе 140 — нет.
Фикс 4. Контекстный prompt — самая недооценённая фича
В Whisper API есть параметр initial_prompt — короткая фраза до 224 токенов, которую модель учитывает как контекст для всего сеанса распознавания. Большинство voice-tool либо не показывают этот параметр в UI, либо прячут в продвинутых настройках, и пользователи не знают про него.
Что туда писать: список ключевых терминов вашей области и пример стиля. Не сами имена, а характер лексики — модель сама подтянет похожие.
Пример для IT-диктовки: «Диктовка кода и архитектурных заметок. Лексика: kubernetes, postgres, langchain, github actions, docker compose, endpoint, webhook, ingress controller. Стиль — короткие технические фразы.»
Пример для юриста: «Диктовка процессуального документа. Лексика: ходатайство, обременение, правопреемство, истец, ответчик, апелляция, кассация. Стиль — официально-деловой, длинные сложноподчинённые предложения.»
Где это поле в реальных сервисах:
- Диктуй — настройки транскрибации, поле «Контекст распознавания».
- SuperWhisper — promp-режимы (Modes), создаёте новый Mode и в Custom Prompt пишете контекст.
- faster-whisper — CLI флаг
--initial_prompt "..."или параметр функцииtranscribe(initial_prompt="..."). - Wispr Flow — в текущей версии публичный доступ к initial_prompt не предоставляют; они применяют свой LLM-cleanup поверх, что закрывает похожую задачу другим способом.
Прирост 3–5 пунктов точности на профессиональной лексике сразу, без других правок. Это самый дешёвый и быстрый фикс — 5 минут на написание prompt.
Фикс 5. Словарь подстановок — точечный фикс на повторяющихся именах
Словарь — список из 30–80 ваших типовых слов: имена коллег, термины из вашей сферы, аббревиатуры, названия продуктов и проектов. После распознавания сервис применяет regex-замены по списку: «постгрес» → «PostgreSQL», «лангчейн» → «LangChain», «джиэйчей» → «GitHub Actions», «иван иванович» → «Иван Иванович Петров».
Чем отличается от контекстного prompt: prompt даёт модели общий контекст лексики, словарь точечно правит конкретные слова на стадии post-processing. Они дополняют друг друга — prompt поднимает точность распознавания, словарь правит остаточные ошибки на повторяющихся именах и терминах.
Где словарь штатно есть:
- Диктуй — раздел «Словарь» в настройках, добавляете пары «как услышит Whisper» → «как написать».
- SuperWhisper — Custom Replacements в настройках модели.
- Handy — через конфиг-файл, без GUI-конфигуратора (только для технически продвинутых пользователей).
- faster-whisper — самостоятельная обвязка с regex-словарём после распознавания.
Прирост 4–6 пунктов точности именно на тех словах, где Whisper стабильно ошибался. На IT-mixed-тексте словарь из 50 правильных написаний даёт примерно 60% прибавки от того, что даёт fine-tune модели на тот же корпус — а трудозатраты меньше в 100 раз.
Совет по содержимому: первые 10–15 слов добавляйте после первой недели использования, когда поймёте, какие именно слова Whisper стабильно режет. Не пытайтесь заранее придумать все варианты — половина окажется ненужной.
Фикс 6. Mixed RU+EN — разделение языков
На фразе «давай задеплоим этот endpoint через GitHub Actions» Whisper Large-v3-turbo распознаёт правильно с первого раза — модель обучена на 99 языках одновременно и распознаёт переключения внутри одной фразы без указания раскладки. Win+H и Apple Dictation — нет: они оптимизированы под одну раскладку клавиатуры, и английские слова в русской речи приходят как «эндпойнт», «гитхаб экшнс».
Если уже на Whisper-based решении — проблема mixed RU+EN решена базовой моделью, дополнительные настройки нужны только на редких терминах. Загружаете 15–20 ключевых английских терминов в словарь подстановок (Kubernetes, PostgreSQL, GitHub Actions, REST API, gRPC) — модель будет распознавать их по звучанию, словарь подставит правильное написание.
Если на Win+H или Apple Dictation — фундаментальное ограничение, не лечится настройками. Решение одно: переход на Whisper-based инструмент. Полный разбор почему встроенные ASR не справляются с mixed RU+EN, и какие три способа есть для Word на Windows — в статье «Как включить голосовой ввод в ворде».
Фикс 7. Цифры, единицы, пунктуация
Дата «15 мая 2026» у Whisper нормально становится «15 мая 2026», но «двадцать миллионов семьсот тысяч» часто остаётся прописью. Адреса, телефоны, IBAN-номера, KPP и аналогичные структурированные данные — отдельная боль.
Что помогает:
- В контекстный prompt написать: «использовать цифровой формат для дат, сумм, телефонов, номеров счетов».
- Длинные цифровые последовательности (телефон, ИНН) — диктовать с короткими паузами между группами цифр, чтобы Whisper не склеивал.
- Точные суммы с копейками — диктовать словом-разделителем: «двадцать тысяч пятьсот рублей пятьдесят копеек» вместо «двадцать тысяч пятьсот пятьдесят».
- Пунктуацию — расставлять паузами в речи (короткая пауза = запятая, длинная = точка). Whisper приёмлемо ставит знаки по интонации, но при равномерном темпе без пауз превращает три предложения в одно длинное.
Прирост 1–3 пункта на финансовых, юридических и бухгалтерских документах. На IT-документации эти фиксы малозначимы.
Фикс 8. LLM-post-processing — финальная чистка
Сырой текст после Whisper содержит «эээ», повторы, заминки и иногда неправильно склеенные предложения. Это не ошибка распознавания — это сырая речь как есть. Финальная чистка через LLM закрывает оставшиеся 1–2 пункта читаемости.
Рабочий промпт для чистки (проверен на сотнях абзацев):
Перепиши черновик ниже: убери слова-паразиты, повторы, заминки.
Сохрани стиль речи автора, ключевые цифры и термины не меняй.
Расставь абзацы по смысловым блокам. Не добавляй ничего от себя.
Черновик:
[вставить расшифровку]
Где применять:
- ChatGPT / Claude / Кими / YandexGPT / GigaChat — копируете блок, прогоняете, вставляете обратно.
- Режим трансформации в Диктуй — выделили абзац в любом окне, нажали отдельный хоткей, голосом дали инструкцию, LLM применяет за 5–10 секунд без переключения окон.
- Transforms в Wispr Flow — аналог Режима трансформации, в актуальной версии помечена как Beta.
- Modes в SuperWhisper — заранее настроенные промпт-шаблоны под разные форматы вывода (письмо, технический коммент, голосовая заметка).
Подробный практический разбор того, как использовать LLM-post-processing на длинных воркфлоу — в статье «30 дней печатаю голосом: эксперимент», где описан реальный месяц замены клавиатуры голосом и где LLM-чистка была критичной для финального качества текста.
Накопительный эффект всех восьми фиксов
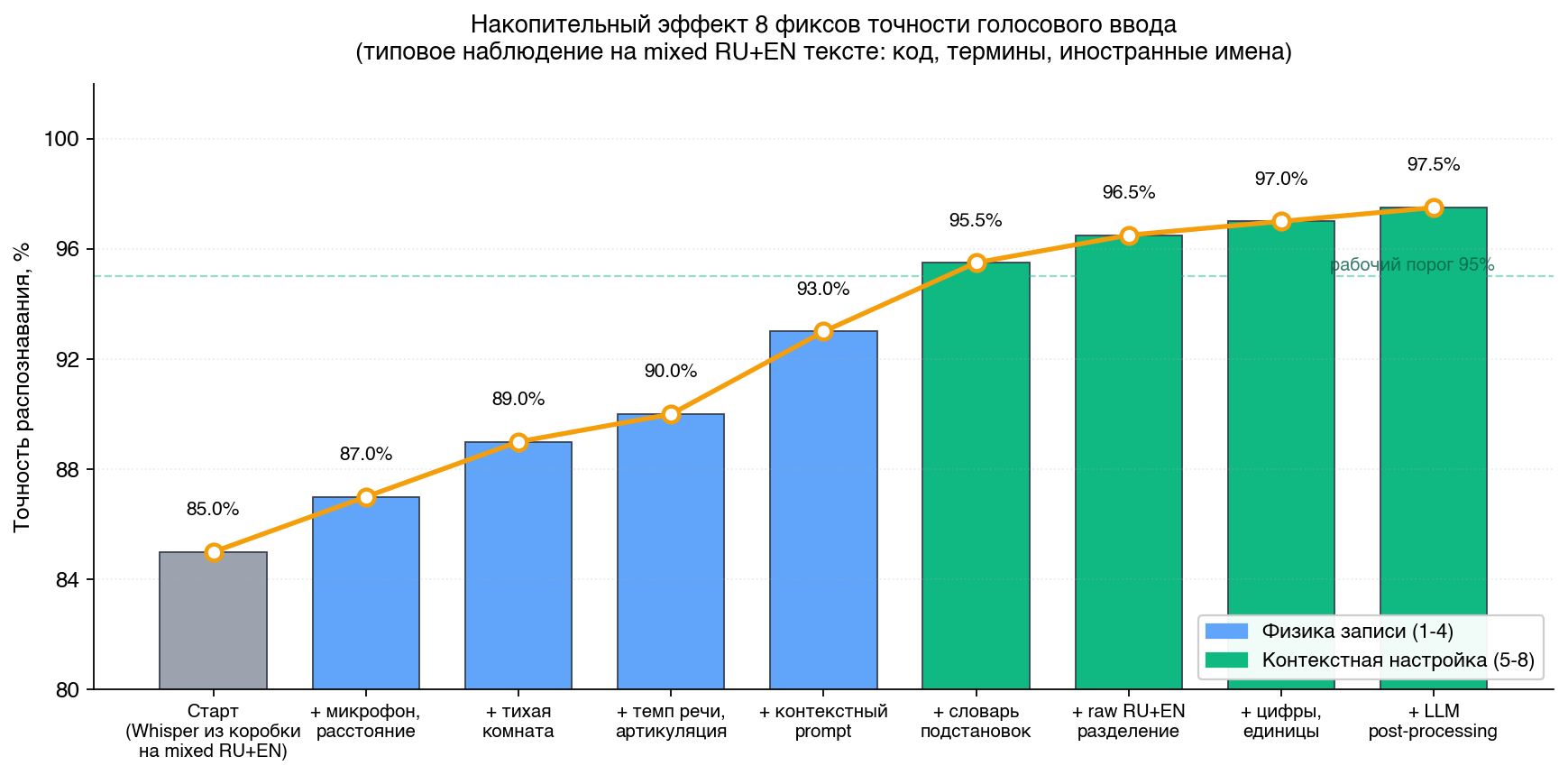
Восемь фиксов выше типично закрывают разрыв с 85% к 97.5% на mixed RU+EN тексте. Это не цифры из идеального эксперимента — это наблюдение из реальной работы команды Диктуй с пользователями, которые приходили с жалобой «точность 87%» и через пару дней настройки выходили на 96–97%.
Распределение прироста по типам фиксов:
- Физика записи (фиксы 1–3 — микрофон, шум, темп) — прибавка 5–8 пунктов
- Контекстная настройка модели (фиксы 4–7 — prompt, словарь, RU+EN разделение, цифровые форматы) — прибавка 6–10 пунктов
- Финальная чистка через LLM (фикс 8) — 1–2 пункта читаемости
Из них самые недоиспользуемые в 2026 году — контекстный prompt (фикс 4) и словарь подстановок (фикс 5). Большинство пользователей о них не знают или не пользуются, хотя суммарно эти два фикса дают +6–10 пунктов точности за час настройки. Когда напрашивается мысль «точность плохая, надо менять сервис» — сначала проверьте эти два фикса в текущем инструменте.
Что объективно не починить
Четыре класса ошибок остаются после всех настроек, и про них стоит знать заранее.
Латинская транслитерация специальных терминов. «Pacta sunt servanda» в речи юриста, «in dubio pro reo» в адвокатской практике, «kubernetes ingress controller» в IT-диктовке — Whisper распознаёт по звучанию, без гарантии правильного латинского написания. Решение — словарь подстановок на эти конкретные термины или ручная правка после распознавания.
Точные цитаты длиной 30+ слов. Whisper умеет распознавать смысл, но не гарантирует орфографическую точность каждого слова. Для журналистов с цитированием и юристов с приведением точных формулировок законов — ручное копирование цитат из источника обходит проблему на порядок дешевле любых настроек модели.
Числовые последовательности с проверкой контрольной суммы. IBAN, ИНН, SWIFT-коды, кадастровые номера — здесь нужна ручная проверка после распознавания. Voice typing для документов с такими номерами имеет смысл только как черновик с обязательной финальной сверкой.
Диаризация говорящих. Whisper не разделяет речь нескольких людей в одном файле — это отдельная задача, требующая модели pyannote.audio или NVIDIA NeMo. Для интервью с двумя собеседниками выбирайте сервис со встроенной диаризацией (Sonix, Otter.ai, Riverside) или планируйте ручную разметку «—» по голосам.
С чего начать прямо сегодня
Если сейчас у вас точность около 85–90% на регулярной работе с голосовым вводом — порядок действий на один вечер.
Первое — записать ту тестовую IT-фразу из раздела «Сначала проверьте» через ваш текущий voice-tool, посчитать ошибки. Это базовая линия для замера эффекта правок.
Второе — поднять микрофон ближе ко рту (10–15 см), выключить кондиционер, занавесить окно. Перезамерить ту же фразу. Прирост 3–6 пунктов от физики записи.
Третье — открыть настройки voice-tool, найти поле «контекстный prompt» или эквивалент, написать туда 2–3 предложения про вашу лексику и стиль. Перезамерить. Прирост 2–4 пункта от контекста.
Четвёртое — за неделю накопить список из 20 слов, на которых Whisper стабильно ошибается. Загрузить их в словарь подстановок. Прирост 4–6 пунктов на конкретно этих словах.
После этих четырёх шагов точность на mixed RU+EN тексте обычно поднимается с baseline 85% к 93–95% — это уже уровень «текст сразу в дело, минимальная финальная редактура». Дальше — фиксы 6–8 (RU+EN разделение, цифры/единицы, LLM post-processing) добавляют ещё 2–3 пункта до целевых 95–97%.
Если после всех восьми фиксов точность держится на 90% или ниже — проблема скорее в записи (микрофон, шум, акцент) или в сильно специфической лексике, где требуется fine-tune модели. Это уже отдельная задача с другим масштабом затрат, и про её окупаемость стоит думать только после исчерпания всех восьми фиксов из этой статьи.
Тем, кто регулярно работает с voice typing на русском и упирается в точность — попробуйте Диктуй. Free-тариф 30 минут навсегда без карты — этого хватит, чтобы за вечер пройти восемь фиксов на одном тексте и сравнить точность до и после. Pro 299 ₽/мес покрывает 5 часов диктовки регулярной работы. Тем, кому привычен CLI и нужен полный контроль над initial_prompt, beam-search и кастомным словарём — faster-whisper на свой ноутбук или сервер выйдет дешевле для десятков часов аудио в месяц.
Михаил Воинский — основатель Диктуй. Свой кейс — какие 30–50 слов вы загрузили в словарь, на каких именах распознавание спотыкается чаще всего, что сработало или не сработало из этих восьми фиксов — пишите на support@diktuy.ru или в @diktuy_help. Соберу из читательских словарей шаблон для нескольких типовых профессий — юрист, врач, разработчик, маркетолог — и опубликую отдельной подборкой через 30 дней.
Часто задаваемые вопросы
Почему точность Whisper на чистом русском декларируется 95%, а у меня 87%?
Декларируемые 95–98% — это OpenAI benchmark на корпусе LibriSpeech и аналогичных академических датасетах: тихая студия, профессиональный микрофон, диктор с натренированной артикуляцией, без специальной лексики. В реальной работе на встроенном микрофоне ноутбука, в обычной комнате, с обычным разговорным темпом и без словаря — реалистичный baseline 85–90%. Все 8 фиксов из этой статьи закрывают разрыв до 96–97%. Дальнейший подъём требует или fine-tune модели на ваш корпус, или ручной редактуры. Подробный разбор архитектуры Whisper Large-v3-turbo и почему «турбо» вариант с восемью декодер-слоями быстрее v3 без потери качества — в [отдельной статье «Whisper Large-v3-turbo на русском»](/blog/whisper-large-v3-turbo-russkiy-2026).
Можно ли обучить Whisper на свою лексику без fine-tune?
Да, двумя способами без переобучения весов модели. Первый — `initial_prompt`: подаёте модели короткий контекст «диктовка договора в гражданском процессе, термины — ходатайство, обременение, правопреемство», модель учитывает этот фон при распознавании. Второй — словарь подстановок на уровне сервиса: после распознавания сервис применяет regex-замены по списку. Прибавка от обоих 5–10 пунктов на специальной лексике. Полный fine-tune Whisper Large-v3-turbo на свой корпус возможен через HuggingFace transformers, но требует 50+ часов размеченных аудио, GPU на ~24 часа обучения и понимания ML-pipeline. Для частной практики или малой команды эти трудозатраты не окупаются — словарь и prompt дают 80% эффекта от fine-tune за 30 минут настройки.
Почему Win+H и Apple Dictation дают 60–70% против 95% у Whisper?
Это разные модели с принципиально разными корпусами обучения. Win+H использует Microsoft Cortana Speech, обученный преимущественно на английских данных с добавлением десятков основных языков. Apple Dictation — собственная модель Apple, оптимизирована под чистый английский и чистые языки региона устройства. Whisper Large-v3 от OpenAI обучен на 680 000 часов многоязычной речи, включая ~30 000 часов русского и явное распознавание переключений языка внутри одной фразы без указания раскладки. На чистом английском Win+H и Whisper сопоставимы (92–95%), на чистом русском Whisper уже опережает на 10–15 пунктов, на mixed RU+EN разрыв доходит до 25–30 пунктов. Это фундаментальное различие моделей, оно не лечится настройками встроенного движка.
Помогает ли локальная модель против облачной для точности?
Не для точности — для приватности и независимости от сети. Локальный faster-whisper или Handy и облачный Диктуй на Whisper Large-v3-turbo запускают одну и ту же модель — точность распознавания идентична. Разница: облако через Groq отвечает за 1–2 секунды на короткую фразу, локальная модель на ноутбуке без видеокарты — 30–60 секунд. Локально побеждает, если нужен полный офлайн (адвокатская тайна, медицинская сессия с конфиденциальными данными, рабочая среда без сети). Подробный разбор open-source локального решения с практикой — в [отдельной статье про Handy и локальный voice-typing](/blog/handy-open-source-golosovoi-vvod-2026).
Что делать с фоновым шумом в записи диктофона?
Сначала почистить аудио, потом отправлять в распознавание. Бесплатный путь — Audacity (Effects → Noise Reduction): записываете шумовой профиль на участке без речи, применяете ко всему файлу — 5 минут на час записи. Платный, но удобный — Adobe Podcast Enhance, 1 час бесплатно в месяц, веб-инструмент специально под подкастерные записи. Для шумной диктофонной записи (улица, кафе) такая предварительная чистка поднимает точность Whisper на 7–15 пунктов. Без неё та же запись распознаётся на 70–80% против обычных 95%. Подробнее про работу с диктофонными форматами — в [статье «Диктофон в текст: пошагово»](/blog/diktofon-v-tekst-rasshifrovat-2026).
Нужна ли отдельная гарнитура или хватит встроенного микрофона ноутбука?
Для коротких диктовок длиной до 30 секунд встроенный микрофон современного ноутбука (MacBook 2022+, ThinkPad 2023+) даёт приемлемые 90–92% на чистом русском. Для регулярной работы (1+ час в день) гарнитура с направленным микрофоном на расстоянии 10–15 см ото рта поднимает на 4–8 пунктов точности и убирает усталость голоса от лишнего напряжения связок. Рабочий бюджет — 1 500–3 000 ₽ за USB-гарнитуру уровня Logitech H540 или Defender Gryphon 750U. Не нужны дорогие конденсаторные микрофоны Blue Yeti за 12 000 ₽ — для голосового ввода направленный конденсаторный микрофон ловит больше шума окружения, чем USB-гарнитура.
Можно ли заставить голосовой ввод правильно ставить точки и запятые?
Whisper расставляет пунктуацию автоматически по интонационным паузам, и на разговорной русской речи это работает на 70–80% уровне — точки в конце высказываний обычно правильные, запятые внутри сложных предложений часто отсутствуют или стоят не там. Решение в три шага. Первое — говорить с явными паузами в местах знаков препинания (короткая для запятой, длинная для точки). Второе — в контекстный prompt добавить пример пунктуации того стиля, который нужен («деловой стиль, длинные предложения с запятыми, точка с запятой допустима»). Третье — пройти готовый текст через LLM post-processing с инструкцией «расставь пунктуацию по правилам современного русского». Эта связка из трёх шагов на длинных текстах даёт 95%+ корректной пунктуации.
Что не починить никаким словарём и prompt?
Четыре класса ошибок остаются после всех настроек. Первый — латинская транслитерация специальных терминов: «pacta sunt servanda», «in dubio pro reo», «kubernetes ingress controller» — Whisper распознаёт по звучанию, без правильного написания. Второй — точные цитаты длиной 30+ слов: модель умеет распознавать смысл, но не гарантирует орфографическую точность каждого слова. Третий — числовые последовательности с проверкой контрольной суммы (IBAN, ИНН, SWIFT) — здесь нужна ручная проверка. Четвёртый — диаризация: разделение речи нескольких говорящих в одном файле не входит в Whisper и требует отдельной модели (pyannote.audio, NVIDIA NeMo). Если ваш сценарий упирается в эти пределы — нужна или ручная редактура, или специализированный сервис со встроенной диаризацией.