context engineering ∙ vibe coding
Контекст-инжиниринг в 2026: почему он важнее промпт-инжиниринга
Karpathy и Anthropic переключили индустрию с промпт-инжиниринга на контекст-инжиниринг. Разбираю практику и почему голос стал обязательным.
Контекст-инжиниринг — подход, в котором вы подаёте LLM не один промпт, а пакет: роль агента, примеры, ограничения, критерии, метаданные файлов. Термин эндорснули Karpathy и Tobi Lütke (CEO Shopify) в июне 2025, Anthropic опубликовал engineering-гайд в феврале 2026, российский Habr подхватил к маю 2026. Печать 1500–3000 слов контекста занимает 37–75 минут — слишком долго для повседневной работы. Надиктовка той же длины — 10–21 минута, и контекст-инжиниринг становится дневным workflow, а не для отдельных сложных задач.
Контекст-инжиниринг — это управление всем, что попадает в окно LLM: ролью, примерами, ограничениями, критериями, метаданными. Промпт — частный случай, один из пяти-семи слотов.
Andrej Karpathy сжатую формулу выдал в июне 2025 — твит из шестнадцати слов о том, что термин «context engineering» точнее описывает индустриальную работу с LLM, чем «prompt engineering». На западном AI-Twitter за две недели формулировка стала стандартом, в феврале 2026 Anthropic опубликовал собственный engineering-гайд под этим зонтиком, российский Habr-сегмент догнал к маю 2026. Разбираю практику этого перехода — что именно поменялось в моём workflow, почему печать перестала справляться, и зачем для контекст-инжиниринга нужен голос. По дороге задеваю смежные темы — vibe coding на русском и сравнение восьми сервисов транскрибации 2026, чтобы статья ложилась в общий хаб voice-инструментов.
Раскрытие: я делаю Диктуй — voice-typing для разработчиков. Эта статья — методологическая: 80% объёма про сам подход контекст-инжиниринга, который работает в любом voice-tool на Whisper Large-v3 (SuperWhisper, Wispr Flow, Handy, faster-whisper). UX-моменты Диктуя упомянуты только там, где функция конкретно решает шаг workflow (свёртка контекст-пакета через Режим трансформации). Где у конкурентов сильнее — отмечаю как есть.
Откуда взялся контекст-инжиниринг как термин
Karpathy запостил в июне 2025: «+1 for context engineering over prompt engineering. People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step» (X post). Тобиас Лютке (CEO Shopify) в тот же день поддержал термин публичным эндорсментом.
Параллельно похожая мысль зрела в LangChain и LlamaIndex сообществах с конца 2024 — но без короткой формулы. Karpathy её собрал и приклеил к подходу.
В начале 2026 Anthropic опубликовал инженерный гайд «Effective context engineering for AI agents», где определил термин как «designing and managing the complete information ecosystem that an LLM accesses during operation». Промпт-инжиниринг тут понизили до подкатегории — это просто одна из нескольких ролей в контекст-пакете.
В феврале 2026 Karpathy сделал второй акцент в твите: новая норма работы с агентами — «вы не пишете код 99% времени, вы дирижируете агентами, которые это делают, и осуществляете надзор». Самый ценный навык 2026, по его словам, не кодинг, а написание точных, недвусмысленных спецификаций, которые AI-агенты могут выполнить. Спецификации в этой формулировке — синоним контекст-пакета. К июлю 2026 это дошло до отдельных продуктов — ChatGPT Work и Claude Cowork: агенту поручают рабочую задачу целиком, и качество результата упирается ровно в полноту контекста на входе.
Российский Habr подхватил тему статьёй «От Vibe Coding к Agentic Engineering» в марте 2026, vc.ru и Ведомости разогнали к апрелю. К маю 2026 термин «контекст инжиниринг» в Wordstat показывает 210 запросов/мес — это вход в массовый дискурс с нуля за два месяца.
Пять ролей контекст-пакета
К началу 2026 индустрия пришла к консенсусу о структуре. Эта структура сформулирована независимо в Anthropic Engineering Blog и в IBM Research, и она же лежит в основе open-source гайда davidkimai/Context-Engineering (handbook вдохновлён лекциями Karpathy и 3Blue1Brown).
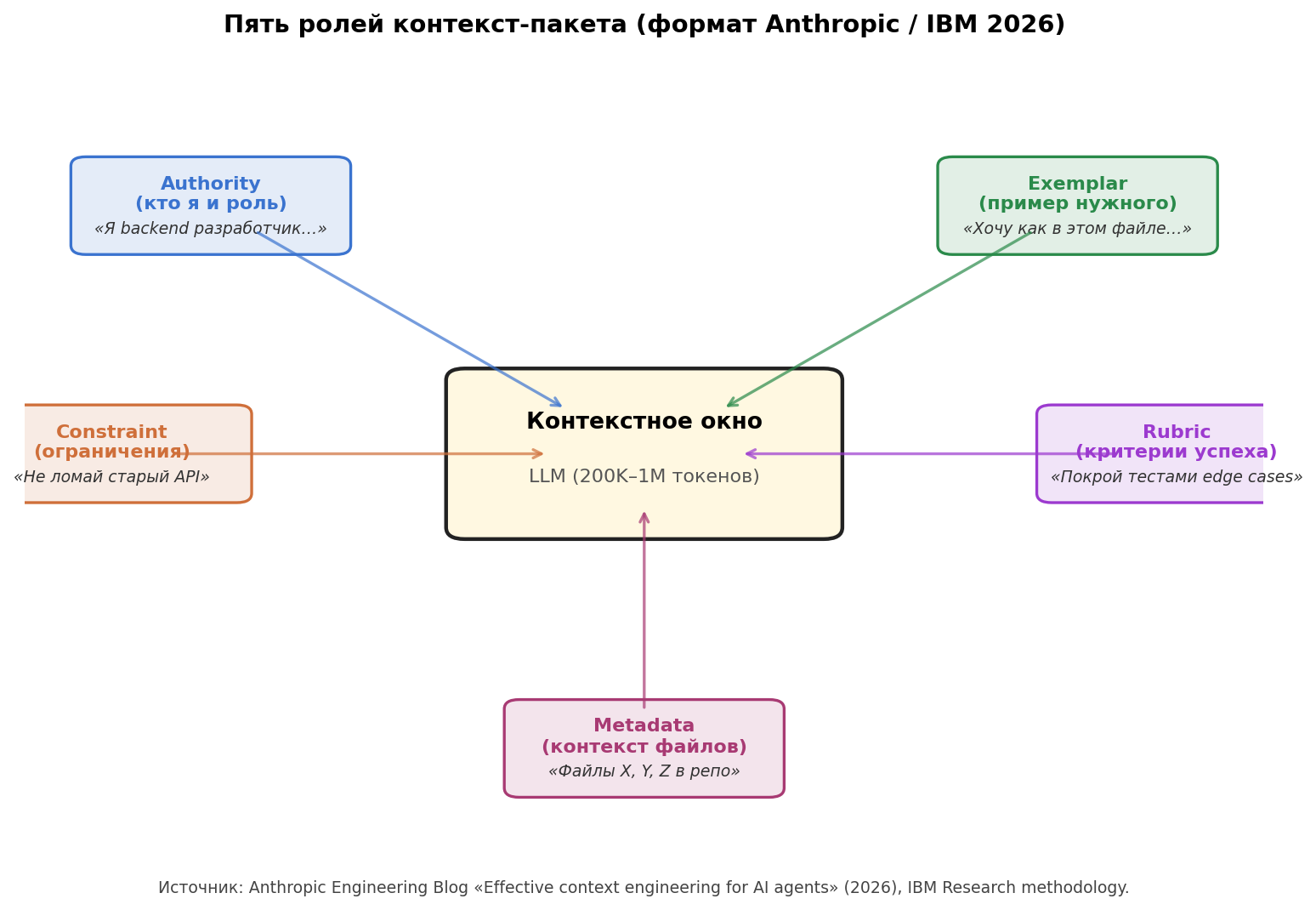
Authority — кто действует и в какой роли. Не «ты — senior backend разработчик» (избитая формула), а «я разрабатываю API gateway для команды из 4 человек, использую FastAPI, метрики через Prometheus, дежурный pager — мой; ответы давай в тоне man pages, без маркетингового жанра». Для агента это привязка к контексту команды и стилю общения.
Exemplar — один или несколько конкретных примеров желаемого результата. Например: «Вот как мы делаем эндпоинты в этом проекте» — и приложить код одного существующего endpoint'а. Без exemplar агент пишет «в среднем по индустрии» — то есть скорее не как у вас. С exemplar выдаёт код, который ложится в кодовую базу без правок.
Constraint — что нельзя ломать или менять. «Не трогай старый API на /v1/, новый делай только на /v2/». «Не добавляй новые зависимости — используй только то что в requirements.txt». «Тесты должны проходить за 60 секунд на CI». Constraint критичен в production: без него агент делает «оптимизацию» которая ломает обратную совместимость.
Rubric — критерии успеха, по которым агент сам проверит работу. «Прежде чем считать готовым: проверь что все тесты проходят, что не сломан линт, что эндпоинт возвращает 422 на невалидном payload, что в логах нет PII». Rubric превращает агента из «дал ответ» в «дал ответ и сам проверил». Это убирает половину итераций ревью.
Metadata — какие файлы подгрузить, текущее состояние, история шагов. В Cursor и Claude Code это подгружается полуавтоматически (открытые файлы, history контекст), но точечно нужно подсказывать: «посмотри в models/user.py:42-78, там типы которыми оперируешь». Metadata экономит токены — агент не сканирует весь репозиторий, а сразу идёт в нужное место.
В сумме на типовую задачу средней сложности контекст-пакет — 1200–2500 слов. Это не «промпт». Это краткий технический бриф, который раньше писали для подрядчика на фрилансе.
Почему промпт-инжиниринг сдулся
В 2023 году контекстное окно GPT-3.5 было 4 096 токенов — это ~3 000 слов. В таком окне был смысл искать «идеальную формулировку запроса» — место под контекст просто не помещалось. Промпт-инжиниринг тогда был про сжатие смысла в 50–200 слов.
К 2026 году контекстное окно стандартных моделей — 200К токенов (GPT-5.5, Claude Opus 4.7, Composer 2.5), Gemini 2.5 Pro даёт 1М, Magic Frontier — до 100М. Места под фоновую информацию хватает на маленький технический справочник.
Проблема сместилась. Уже не нужно искать «идеальную формулировку» — модели достаточно умны, чтобы понять и кривой запрос. Узким местом стало другое: чем заполнить освободившееся пространство, чтобы агент сделал правильно с первого раза.
Andrej Karpathy в технической колонке формулирует это как «delicate art of filling the context window with just the right information». Слово ключевое — filling. Не «as short as possible», а «as relevant as possible». Это перевернутая оптимизация: раньше боролись за сжатие, теперь — за заполнение.
Anthropic в инженерном блоге выводит из этого практическое правило: для большинства задач у модели должны быть не только инструкции, но и «достаточно контекстных опор», чтобы инструкции выполнить надёжно. Прирост качества от добавления хорошо собранного Exemplar — больший, чем прирост от перехода на более дорогую модель.
То есть: контекст-пакет на Composer 2.5 ($0,50/$2,50 за миллион токенов) даёт качество близкое к голому промпту на Claude Opus 4.7 ($15/$75) — в 30 раз дешевле. Это видно по бенчмаркам в разборе Composer 2.5 и подтверждается отчётами cost-conscious команд на Habr и Reddit r/cursor.
Где печать ломается на контекст-инжиниринге
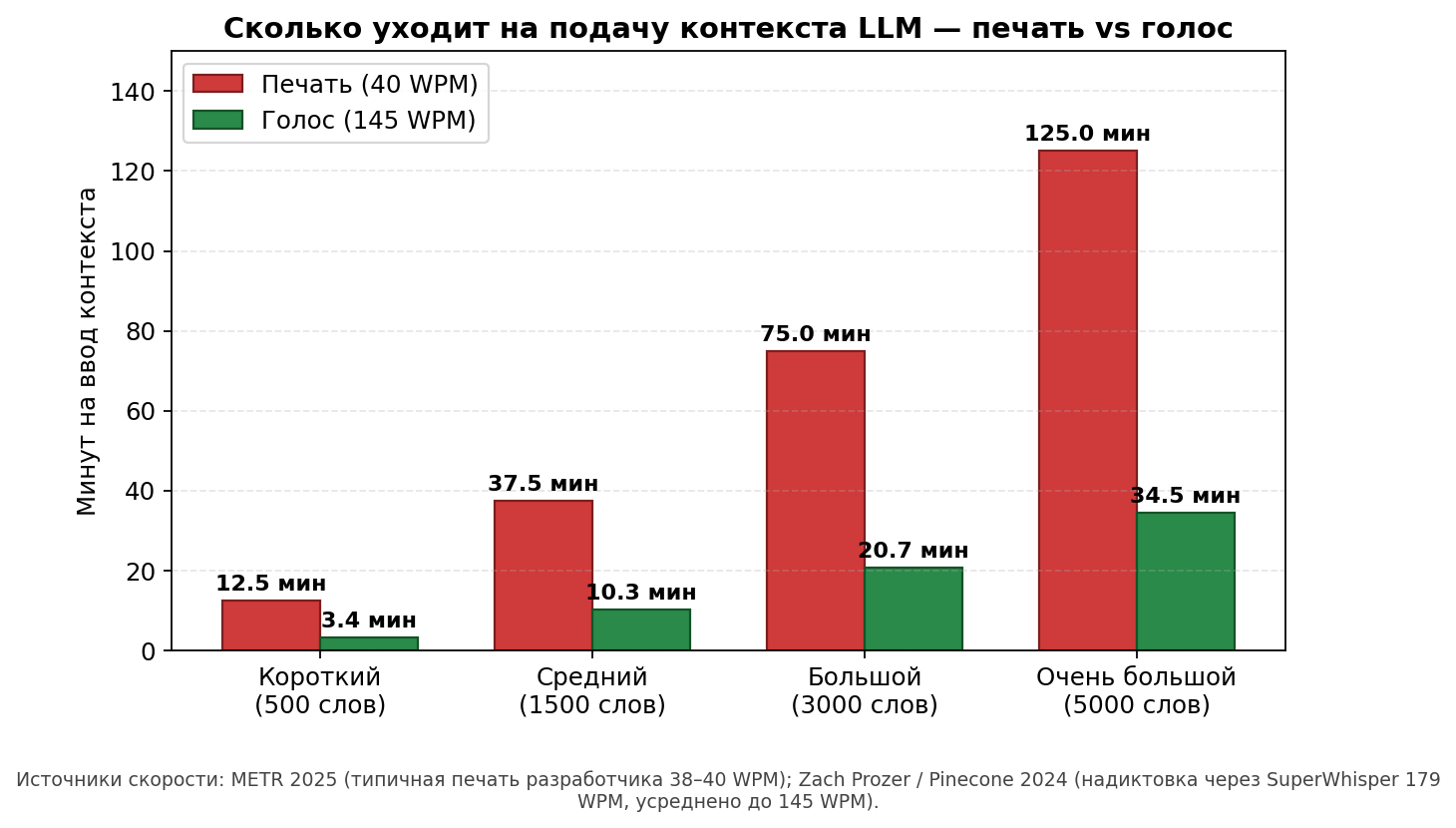
Математика жёсткая. Опытный разработчик печатает 38–40 слов в минуту по бенчмарку METR 2025. Естественная надиктовка — 130–150 слов в минуту, по замеру Zach Prozer (Pinecone) через SuperWhisper — даже 179 WPM.
На контекст-пакет в 1500 слов:
- Печать: 37 минут чистого ввода. Плюс паузы на «найти точное слово» — реально 50–55 минут.
- Голос: 10 минут надиктовки. Плюс 2–3 минуты на правку и AI-чистку — 12–13 минут.
На пакет в 3000 слов (типовая задача с двумя exemplar и подробным rubric) разрыв уходит в полчаса. Печатать 75 минут — это уже не «оформление задачи», это половина дневной работы. Поэтому при печати контекст-инжиниринг физически не помещается в обычный рабочий день: ты либо пишешь сокращённый пакет (и теряешь качество ответа), либо отказываешься от подхода в пользу старого «короткий промпт + итерации».
С голосом тот же пакет умещается в 10–15 минут — и контекст-инжиниринг становится повседневной практикой, а не «для отдельных сложных задач».
Что изменилось у меня за три недели на голосовом контекст-инжиниринге
Я начал собирать контекст-пакеты целиком 4 мая 2026, после того как опубликовал разбор voice-prompting в Cursor и Claude Code и в комментариях коллега спросил, использую ли я именно тот workflow, который описываю. Оказалось — наполовину. До тех пор я надиктовывал тело задачи, но Authority/Constraint/Rubric писал руками или просто пропускал.
За три недели полного контекст-инжиниринга через голос три вещи поменялись:
Итераций с агентом стало меньше в 2–3 раза. Раньше типичный сценарий был: дал короткий промпт → агент сделал не то → уточнил → агент почти сделал → уточнил → готово. Это 3–4 итерации. С полным контекст-пакетом обычно достаточно одной итерации, изредка двух (если в Constraint забыл что-то важное).
Качество кода ближе к существующему стилю репозитория. Exemplar — самое недооценённое поле. Когда даёшь агенту 50 строк из существующего endpoint'а как «вот наш стиль», он эту стилистику копирует. Без exemplar он пишет «среднестатистический FastAPI код», и потом 15 минут уходит на причёсывание под наш стиль.
Усталость от рук упала. Я печатаю с подросткового возраста — пальцы натренированные, до этого года это не было проблемой. Но 75 минут печати на одну задачу — это пять-семь задач в день в режиме контекст-инжиниринга, и к вечеру руки ноют. Голос убирает физическую нагрузку: говорить три часа в день вместо печатать семь — несравнимо легче.
Один трезвый момент: контекст-инжиниринг через голос окупается только если у тебя реально длинные пакеты (1000+ слов). Если задача мелкая («поправь типизацию в этом одном файле»), полный пакет — overkill, и обычный короткий промпт быстрее. Поэтому 50–60% задач у меня по-прежнему «короткий промпт печатью», а 40–50% — «длинный пакет голосом». Я подробно описал это распределение в личном эксперименте «30 дней голосом».
Workflow контекст-инжиниринга голосом за 4 шага
Это рецепт, к которому я пришёл за месяц проб и ошибок. Не претендую на универсальность — у вас может оптимизироваться иначе, но за стартовую точку годится.
Шаг 1. Шаблон контекст-пакета на одной странице
Заведите markdown-файл в Notion, Obsidian или в репозитории — neutral место, не зависящее от конкретного IDE. Структура:
## Authority
[кто я в этой задаче, какая роль, какой тон ответов]
## Exemplar
[один или несколько примеров желаемого результата — код, текст, формат]
## Constraint
[что нельзя ломать, какие зависимости фиксированы, какие требования к производительности]
## Rubric
[список критериев, по которым агент проверит работу до выдачи]
## Metadata
[файлы подгрузить, состояние системы, история предыдущих шагов]
## Задача
[собственно описание того, что нужно сделать]
Шаблон один раз — и потом просто копируете его в начало любой новой задачи.
Шаг 2. Авто-замены и сниппеты для типовых блоков
Authority и часть Constraint у вас повторяются от задачи к задаче. Не надиктовывайте их каждый раз — заведите автозамены или сниппеты. У меня в Диктуй автозамена: ключевое слово «авторити-backend» разворачивается в готовый блок Authority для backend-задач. Так же «констрейнт-производственный» — раскрывается в стандартный набор production-Constraint'ов («не трогай миграции, тесты должны проходить, не добавляй зависимости»).
Аналог в Wispr Flow — Snippets и Auto Cleanup, в SuperWhisper — Replacements. В faster-whisper и Handy таких автозамен нет — приходится держать в Notion или Raycast Snippets.
Шаг 3. Голосом — переменные части
Exemplar, Rubric и описание задачи каждый раз разные. Их и надиктовываете. Естественная речь течёт связнее печати — длинный Exemplar получается у меня за 90–120 секунд вместо 8–10 минут печати.
Совет: говорите как объясняете коллеге, который только что зашёл в проект. «Слушай, у нас в проекте API gateway, и я хочу добавить новый endpoint для…» — такая формулировка естественнее, чем «You are a senior backend engineer. Add a new endpoint that…». Современные модели разбирают и тот, и другой стиль, но первый получается у вас за полминуты, второй — за пять.
Шаг 4. AI-чистка перед отправкой агенту
Надиктованное содержит «эээ», повторы, оговорки, паразиты. Агент справится и так, но качество слегка падает — модель тратит токены на разбор «не очень чистой» речи.
Я выделяю весь надиктованный контекст-пакет и через Режим трансформации даю команду «убери паразиты, оформи как чистый markdown с разделами Authority/Exemplar/Constraint/Rubric/Metadata, сохрани все факты и примеры». LLM применяет инструкцию — на 1500 слов уходит 8–10 секунд. На выходе чистый, структурированный пакет.
В Wispr Flow аналог — Transforms (в Beta с 1 мая 2026). В SuperWhisper — через систему промптов, но без отдельного hotkey. В Handy и faster-whisper эту чистку придётся делать вручную через копирование в Claude/ChatGPT — это дополнительный шаг с переключением окон.
RU-реалии: какие LLM водить голосом из России
Контекст-инжиниринг работает с любой современной моделью, но не все модели одинаково доступны из РФ. Срез индустрии к концу весны 2026:
Claude Opus 4.8 и Claude Sonnet 4.6 — доступ через Anthropic Console требует валютную карту. Через российские агрегаторы (ProxyAPI, GenAPI, AITunnel, Vsegpt) — рублёвая оплата СБП и картами МИР, наценка 10–20%. Cursor и Claude Code через подписку оформляются у посредников типа Oplatym или GetMeGo за рубли. Opus 4.8 (релиз 28 мая 2026) добавил динамические рабочие процессы — модель сама оркестрирует рой под-агентов под полный бриф, что делает качество контекст-пакета ещё критичнее; разбор — в статье про Claude Opus 4.8.
GPT-5.5 — то же самое: либо валютная карта в OpenAI, либо российский агрегатор. С 5 мая 2026 GPT-5.5 Instant — default-модель в ChatGPT для всех тарифов, ответы стали короче на 30% при той же сути, что делает её особенно удобной для контекст-инжиниринга (см. разбор GPT-5.5 в России).
Cursor Composer 2.5 — внутри Cursor, доступен по основной подписке Cursor Pro/Pro+ через посредников. По соотношению цена/качество — лучший выбор под контекст-инжиниринг: $0,50/$2,50 за миллион токенов, паритет с Opus 4.7 на 80% задач. Разбор бенчмарков — в статье про Composer 2.5.
YandexGPT 5.1 Pro и GigaChat 3.0 — российские модели, оплата напрямую в рублях, без посредников. Качество контекст-инжиниринга на русском у обоих хорошее на средних задачах, но на сложном reasoning отстают от Opus/GPT-5.5. Подходят для задач с конфиденциальными данными, где трансграничная передача в США юридически сложна.
OpenAI Realtime API (GPT-Realtime-2, GPT-Realtime-Translate, GPT-Realtime-Whisper, выпущены 7 мая 2026) — для streaming-сценариев и low-latency агентов. Доступ из РФ через те же агрегаторы. Подробности — в разборе голосового GPT и Realtime API.
Контекст-пакет, надиктованный голосом, одинаково хорошо ложится во все перечисленные модели — формат универсальный. Голос как input modality не зависит от того, какой LLM на принимающей стороне.
Где контекст-инжиниринг ещё не окупается
Подход не панацея. Три кейса, где полный контекст-пакет хуже короткого промпта:
Мелкие точечные правки в знакомом коде. «Поменяй тип параметра с str на UUID4» — задача на 30 секунд. Собирать контекст-пакет 5 минут — overkill. Печатать короткую инструкцию руками — быстрее и точнее.
Exploratory разговоры с моделью. Когда сам ещё не знаешь, что хочешь — обсуждаешь архитектуру, ищешь подход. Здесь контекст-пакет вреден: жёсткая структура убивает свободу разговора. Лучше короткие итеративные сообщения.
Совсем новый для вас домен. Если вы первый раз касаетесь, например, embedded-разработки или machine learning, у вас ещё нет Exemplar и нечем заполнить Rubric. Сначала наберите опыт через 10–15 коротких задач, потом можете возвращаться к полному пакету.
В остальном — типовые production-задачи на знакомой кодовой базе, новые фичи в существующем сервисе, рефакторинг с сохранением API, написание тестов — контекст-инжиниринг через голос окупается. Это 50–70% работы среднего разработчика, и именно на этом срезе экономия времени самая чувствительная.
Что дальше
Контекст-инжиниринг — не новая мода, это эволюция взаимодействия с LLM, к которой индустрия пришла после расширения контекстного окна с 4К до 200К–1М токенов. Промпт-инжиниринг не исчезает — он становится подкатегорией контекста, одной из пяти ролей в пакете. Но идея «найти идеальную формулировку короткого запроса» больше не центральная — её сменила идея «правильно заполнить окно».
Голос здесь — не единственный, но самый практичный input modality. Без него контекст-инжиниринг физически не помещается в дневной workflow: 75 минут печати на одну задачу — это слишком много. С ним пакет на 1500–3000 слов занимает 10–20 минут, и подход становится повседневным.
Если хотите попробовать прямо сейчас:
- Возьмите шаблон контекст-пакета из этой статьи (Шаг 1), сохраните в Notion / Obsidian.
- Поставьте voice-tool. На Mac/Windows без валютной карты — Диктуй, 30 минут диктовки навсегда без карты, 299/599 ₽ за Pro/Unlimited, оплата СБП и картами МИР. На Mac с валютной картой — SuperWhisper (используется Karpathy). На Linux open-source — Handy, разобран в отдельной статье.
- Попробуйте на одной типовой задаче собрать полный пакет голосом, отправить в Cursor / Claude Code / Кими и сравнить с обычным коротким промптом. На сложных задачах разница ощущается с первого раза, на простых — не ощущается совсем.
У вас уже сложился собственный шаблон контекст-пакета или вы пришли к другой структуре ролей? Поделитесь в @evocoders или напишите на support@diktuy.ru. Мы собираем подборку рабочих шаблонов от русских vibe-coder'ов 2026 — опубликуем отдельной статьёй через 30–45 дней.
Михаил Воинский — основатель Диктуй. Свой шаблон контекст-пакета, рабочий рубрик-чек-лист для AI-агентов, кейс где контекст-инжиниринг провалился — пишите на support@diktuy.ru или в @diktuy_help. Подборку шаблонов от русских vibe-coder'ов соберу в отдельную публикацию через 30–45 дней с указанием контрибьюторов.
Часто задаваемые вопросы
Чем контекст-инжиниринг отличается от промпт-инжиниринга простыми словами?
Промпт-инжиниринг — это искусство одной формулировки: как сформулировать запрос так, чтобы LLM ответил лучше. Контекст-инжиниринг — это управление всем, что попадает в контекстное окно модели: системная роль, история разговора, подгруженные документы, доступные инструменты, память, ограничения и критерии успеха. Промпт — частный случай контекста, один из пяти-семи слотов. Когда контекстное окно выросло с 4К до 200К–1М токенов, проблема сместилась с «как сформулировать вопрос» на «чем заполнить окно, чтобы агент сделал правильно с первого раза».
Кто придумал термин «context engineering» и когда?
Публично термин закрепился в июне 2025 после параллельных постов Andrej Karpathy (бывший директор по AI в Tesla, со-основатель OpenAI) и Tobi Lütke (CEO Shopify) на X. Karpathy сжатую формулу выдал в [твите](https://x.com/karpathy/status/1937902205765607626): «+1 for context engineering over prompt engineering. People associate prompts with short task descriptions… in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step». До этого схожие идеи обсуждались в LangChain и LlamaIndex сообществах, но именно июнь 2025 — момент институционализации. Anthropic опубликовал собственный engineering-гайд [«Effective context engineering for AI agents»](https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents) в начале 2026.
Что входит в контекст-пакет — пять ролей по Anthropic / IBM?
Это формат, к которому индустрия пришла к 2026 году: **Authority** — кто действует, его роль и компетенции; **Exemplar** — один или несколько примеров желаемого результата; **Constraint** — ограничения, что нельзя ломать или менять; **Rubric** — критерии успеха, по которым агент сам проверит свою работу; **Metadata** — какие файлы подгрузить, состояние системы, история предыдущих шагов. На практике в Cursor или Claude Code половина слотов подгружается автоматически (Metadata — открытые файлы, Authority — system prompt IDE), но Exemplar/Constraint/Rubric пишет разработчик. Это 70–80% объёма всего контекст-пакета.
Почему именно голос, а не быстрая печать или сниппеты?
Математика простая. Опытный разработчик печатает 38–40 слов в минуту по [METR 2025](https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/). Естественная надиктовка — 130–150 слов в минуту, и сама речь течёт связнее, без поиска формулировок. На контекст-пакет в 1500 слов печать тратит 37 минут, голос — 10 минут. Сниппеты решают часть Authority/Constraint (типовые блоки заранее заготовлены), но Exemplar и Rubric каждый раз разные — их и надиктовываешь. Голос — единственный input modality с реалистичной пропускной способностью на 1000+ слов в день, который не убивает руки и не превращается в фоновую работу.
Это работает для русского языка или только для английских промптов?
Работает для обоих, и mixed RU+EN — самый частый кейс у российских vibe-coder'ов. Whisper Large-v3-turbo (модель под капотом SuperWhisper, Wispr Flow, Handy, Диктуй) обучен на 99 языках одновременно, распознавание переключений языка внутри одной фразы корректное — «обработай webhook через middleware, валидируй через zod, верни 422 если payload не прошёл схему» распознаётся как написано. Встроенные решения (Win+H, Apple Dictation) на mixed речи падают в качестве на 30–50% — для контекст-пакетов их не использовать. Подробный разбор voice-tools для русского — в [статье «Голосовой ввод в Cursor и Claude Code на русском»](/blog/golosovoi-vvod-cursor-claude-code-2026).
Контекст-инжиниринг работает только с премиум-моделями типа Opus 4.7 и GPT-5.5?
Нет, наоборот — он окупается даже сильнее на средних моделях. Cursor Composer 2.5 (релиз 18 мая 2026, дообученный Kimi K2.5) при $0,50/$2,50 за миллион токенов на хорошо собранном контекст-пакете даёт качество близкое к Opus 4.7 на типичных задачах. Анализ Cursor: правильный контекст для модели среднего уровня важнее, чем reasoning топовой модели на куцем промпте. На GPT-5.5 и Claude Opus 4.7 контекст-пакет тоже даёт прирост, но дельта меньше — модели сами умеют достраивать недостающее. Подробный разбор Composer 2.5 — в [статье «Cursor Composer 2.5: длинные промпты голосом»](/blog/cursor-composer-2-5-russkiy-2026).
Как организовать контекст-инжиниринг workflow на практике — за какие минимальные шаги?
Четыре шага. **Шаг 1** — заведите шаблон контекст-пакета (markdown-файл в Notion, Obsidian или просто в репо) с пятью секциями: роль, пример, ограничения, критерии, метаданные. **Шаг 2** — типовые блоки (Authority для backend / frontend / data, стандартные Constraint вроде «не ломай старый API») сохраните как автозамены или сниппеты. **Шаг 3** — переменные части (Exemplar, Rubric, описание задачи) надиктовывайте голосом. **Шаг 4** — перед отправкой агенту прогоняйте надиктованное через AI-чистку (Режим трансформации в Диктуй, Rewrite в Wispr Flow, ручная Claude/ChatGPT-команда «убери паразиты, оформи как чистый промпт»). На полный пакет уходит 5–8 минут вместо 30–40 при печати.
В России можно использовать топовые AI-модели для контекст-инжиниринга — Opus 4.7, GPT-5.5 — без валютной карты?
Да, через российские агрегаторы AI API: ProxyAPI, GenAPI, Vsegpt, AITunnel, Polza AI, VseLLM. Это российские юридические лица с оплатой через СБП и картами МИР, под капотом — те же OpenAI, Anthropic, Google Gemini, Mistral. Наценка 10–20% над оригинальным прайсом, но это решает доступ к моделям без прокси-карт и санкционных рисков. Для voice-prompting в Cursor подписка оформляется через посредников типа Oplatym или GetMeGo — пополняют ваш Cursor-аккаунт за рубли через СБП за 30–60 минут. Подробности доступа к GPT-5.5 — в [отдельной статье про GPT-5.5 в России](/blog/gpt-5-5-v-rossii-2026), про OpenAI Realtime API через российские агрегаторы — в [разборе голосового GPT и Realtime API](/blog/golosovoi-gpt-openai-realtime-rossiya-2026).