Claude Opus 4.8: динамические процессы и голос в мае 2026
Claude Opus 4.8 вышел 28 мая 2026: динамические процессы запускают до 1000 агентов. Разбираю механику, цены, доступ из РФ и где окупается голос.
Claude Opus 4.8 вышел 28 мая 2026 — через 41 день после 4.7. Главное новшество — динамические рабочие процессы: Claude сам пишет JavaScript-скрипт-оркестратор и запускает под ним до 1000 под-агентов (16 одновременно), вплоть до миграций на сотни тысяч строк кода от старта до merge. Обычная цена не изменилась ($5/$25 за миллион токенов), в 3 раза подешевел только fast mode. Из России Anthropic напрямую недоступен — нужна подписка через посредника или российский API-агрегатор.
Через 41 день после Opus 4.7 Anthropic выпустила Opus 4.8 — и интереснее в этом релизе не прирост на бенчмарках, а то, что модель теперь сама пишет программу-оркестратор и запускает под ней до тысячи под-агентов. Релиз вышел 28 мая 2026, на дату этого разбора ему три дня. Русские разборы уже появились (на vc.ru и Habr — подробные авторские, не переводы), но почти все упрощают самую новую механику и путают пару важных деталей. Это и разберу — что реально нового, сколько стоит, как зайти из России, и в одном блоке ближе к концу — где здесь окупается голос.
Перед разбором — про мою предвзятость: я делаю Диктуй, голосовой ввод для разработчиков. Поэтому про голос здесь будет ровно один блок ближе к концу, а первые четыре пятых текста — про саму модель и оркестрацию, без привязки к продукту. Где Opus 4.8 не подходит или где деталь не подтверждена первоисточником — пишу как есть.
Claude Opus 4.8 — обновление флагманской модели Anthropic от 28 мая 2026 с главным новшеством в виде динамических рабочих процессов: Claude сам пишет JavaScript-скрипт-оркестратор и запускает под ним рой под-агентов (до 16 одновременно, до 1000 за запуск), вплоть до кодовых миграций от старта до влитого PR. Обычная цена и контекстное окно не изменились, model id — claude-opus-4-8.
Что изменилось 28 мая 2026
По официальному анонсу Opus 4.8 «строится на Opus 4.7 с улучшениями по бенчмаркам» и доступен «сегодня по той же цене». Ключевые факты прямо со страницы и из документации Claude API:
- Цена обычного режима не изменилась — $5 за миллион входных токенов, $25 за миллион выходных, как у Opus 4.7.
- Контекстное окно 1M токенов по умолчанию на Claude API, Amazon Bedrock и Vertex AI (200K на Microsoft Foundry). Максимальный вывод — 128K токенов, граница знаний — январь 2026.
- Уровень усилия по умолчанию снижен с xhigh (у Opus 4.7) до high.
- Системные сообщения посреди диалога в Messages API — можно обновлять инструкции по ходу задачи, не сбрасывая кэш промпта.
- Качественный сдвиг в надёжности — по данным Anthropic, модель примерно вчетверо реже пропускает изъяны в коде и чаще сама отмечает места, где не уверена в результате.
41 день между 4.7 и 4.8 — нетипично короткий цикл для Anthropic, и он совпал по времени с релизами OpenAI и Google. Но содержательно главное в 4.8 не «ещё мощнее модель», а новый способ её использовать.
Что такое динамические рабочие процессы

Это не маркетинговая абстракция, механика задокументирована. По документации Claude Code, динамический процесс — это JavaScript-скрипт, который Claude пишет сам под вашу задачу, а отдельный runtime исполняет его в фоне, пока ваша сессия остаётся отзывчивой.
Ключевая идея — где живёт план. Скрипт сам держит цикл, ветвления и промежуточные результаты, поэтому в контекстном окне модели остаётся только финальный ответ. Рой агентов может отработать десятки шагов, а контекст не забивается их перепиской — это и снимает старый потолок «агент потерял начало задачи к концу».
Лимиты названы прямо: до 16 агентов одновременно (меньше на слабом CPU) и до 1000 агентов всего за один запуск — последнее как защита от бесконечных циклов. Это потолок, а не норма: типичная задача укладывается в десятки под-агентов.
Практический предел возможностей по анонсу — Claude Code с Opus 4.8 берётся за миграции на сотни тысяч строк кода от старта до влитого PR, используя существующий набор тестов как планку приёмки. Из ярких сторонних кейсов: по сообщению Jarred Sumner (приводит MarkTechPost), переписывание Bun дало порядка 750 тысяч строк Rust с прохождением 99,8% тестов за одиннадцать дней от первого коммита до merge. Это сторонний пример, не официальная метрика Anthropic, но масштаб показателен.
Важная оговорка по точности: документация пишет, что процесс может заставить независимых агентов адверсариально перепроверять находки друг друга — то есть это опциональный паттерн качества, а не гарантированное поведение каждого процесса. Несколько русских разборов подают это как «агенты всегда опровергают друг друга» — так писать неверно.
Статус фичи — research preview. Нужен Claude Code v2.1.154 или новее, доступна на всех платных планах. На Pro по умолчанию выключена (включается в /config), на Max и Team включена.
ultracode и уровни усилия: что путают в большинстве разборов
Здесь больше всего неточностей в русскоязычных пересказах, поэтому отдельный блок.
Уровни усилия (effort) у Opus 4.8 — это low, medium, high, xhigh, max, по умолчанию high (у Opus 4.7 дефолт был xhigh). В интерфейсе claude.ai те же уровни названы иначе для пользователя — «extra» соответствует xhigh, и «max».
А ultracode — не шестой уровень модели, а настройка именно Claude Code. По документации Claude Code: /effort ultracode отправляет модели уровень xhigh и вдобавок даёт Claude право автоматически запускать динамические процессы для крупных задач. Это сессионная настройка — при новой сессии сбрасывается. То есть ultracode = «максимум рассуждения + разрешение собрать рой агентов сам». Если в разборе ultracode называют просто уровнем усилия модели — это ошибка.
Что подешевело, а что нет
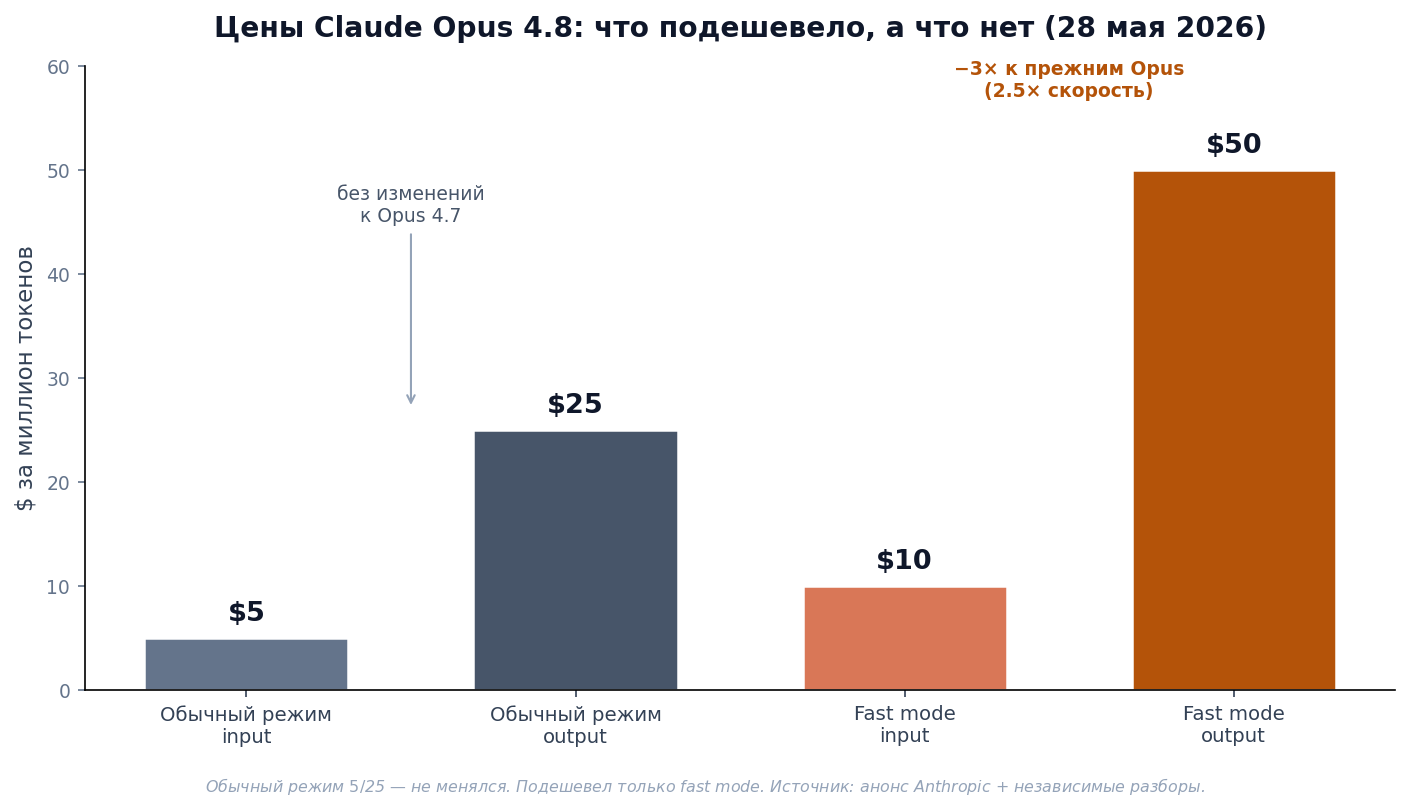
Самая частая ошибка русских заголовков — «вышел Opus 4.8, который в разы дешевле». Это неправда для обычного режима.
- Обычный режим: $5 / $25 за миллион входных/выходных токенов. Не изменился относительно Opus 4.7, 4.6 и 4.5.
- Fast mode: $10 / $50 за миллион токенов. Вот он стал в 3 раза дешевле, чем у предыдущих Opus, при скорости вывода до 2,5× выше. Это та же модель, просто высокоскоростная конфигурация; статус — research preview, нужны включённые usage credits.
То есть «подешевело» относится только к быстрому режиму. Для большинства задач, где важна не латентность, а стоимость или длинная автономная работа, остаётся обычный режим по прежней цене.
Бенчмарки и одно улучшение, которое важнее цифр
Из официального анонса дословно подтверждается результат 84% на Online-Mind2Web (агентные задачи в браузере). Конкретных чисел по SWE-bench, GPQA и AIME в тексте анонса нет — основная таблица на странице рендерится скриптом, поэтому цифры вроде SWE-bench Verified около 88% корректнее брать как сторонние оценки (vellum, llm-stats), а не как официальную метрику. Точные показатели — в System Card модели.
Но интереснее цифр — заявленный сдвиг в надёжности. Anthropic пишет, что Opus 4.8 примерно вчетверо реже пропускает изъяны в коде и чаще сам отмечает, где не уверен в результате. Для агентной работы это важнее лишнего процента на бенчмарке: когда рой под-агентов часами пишет код в фоне, «модель сама поднимает флаг на сомнительном месте» экономит больше, чем «модель на 1 пункт точнее».
Opus 4.8 против GPT-5.5 и предыдущего Opus 4.7
По сторонним разборам (the-decoder, vellum) Opus 4.8 обходит и Opus 4.7, и GPT-5.5 на кодовых бенчмарках вроде SWE-bench Verified — но разрыв небольшой, единицы процентов, и опять же это не официальные числа Anthropic. Практическая разница не в баллах, а в фиче: своего аналога динамических процессов уровня Opus 4.8 (когда модель сама пишет оркестратор и гонит рой агентов до merge) у GPT-5.5 на конец мая 2026 нет. Зато у GPT-5.5 лучше отлажен доступ из России через API-агрегаторы и сильнее экосистема под алгоритмические задачи — её воркфлоу с голосом я разбирал в отдельной статье про GPT-5.5 в России. Грубое правило выбора: Opus 4.8 — под крупную агентную работу и миграции, GPT-5.5 — под сложный одиночный reasoning, Cursor Composer 2.5 — под повседневный кодинг по цене.
Как получить доступ из России
Anthropic официально не обслуживает Россию и не принимает российские карты — это прямо подтверждают свежие разборы на vc.ru и Habr от конца мая 2026. Рабочие пути без VPN:
- Подписка Claude (Pro/Max) через посредника. Oplatym, GetMeGo и аналогичные оформляют подписку на ваш аккаунт за рубли через СБП за 30–60 минут. Именно подписка нужна для Claude Code и динамических процессов — это подписочная фича, не чистый API.
- Модель по API через российский агрегатор. ProxyAPI, GenAPI, Vsegpt, AITunnel — российские юрлица с оплатой в рублях, под капотом те же модели Anthropic. Но это доступ к модели, а не к Claude Code; завязанную на план оркестрацию через агрегатор стоит уточнять отдельно.
- Российские модели без посредников. YandexGPT 5.1 Pro и GigaChat доступны напрямую за рубли. На сложном reasoning уступают Opus 4.8, но закрывают задачи с конфиденциальными данными, где трансграничная передача в США юридически неудобна.
Практический совет тот же, что и для других зарубежных моделей: держать два разных API-агрегатора на случай, если один временно ляжет.
Где здесь голос
Теперь обещанный единственный продуктовый блок. Динамические процессы меняют не только мощность, но и саму роль человека в цикле. Раньше вы давали короткий промпт и итеративно правили результат. С оркестрацией работа смещается к другому: вы пишете развёрнутое ТЗ для процесса, который дальше отработает десятки шагов сам.
И тут важная экономика: цена неполного брифа выросла. Если процесс автономно отрабатывает рой агентов в фоне, а вы забыли в ТЗ ограничение или критерий приёмки — он уедет не туда дороже, чем при обычном коротком промпте, где вы поправляете на лету. Поэтому бриф хочется делать полным: контекст, что нельзя ломать, по каким тестам считать готовым, какой стиль кода.
Полный бриф — это 200–500 слов. Печатать его 5–7 минут (с переключением раскладки на английские термины и опечатками), надиктовать — 60–120 секунд: естественная речь идёт 130–150 слов в минуту против печати 38–40. Голосом проще не лениться и проговорить все оговорки, которые иначе пропустишь. Я сам ставлю задачи для агентов именно так — надиктовываю ТЗ целиком, потом одним движением чищу его от «эээ» и повторов перед отправкой. Подробнее про методологию полного контекст-пакета — в разборе контекст-инжиниринга 2026, а про то, почему длинные промпты окупаются сильнее именно на свежих агентских моделях — в статье про Cursor Composer 2.5.
Инструмент здесь вторичен — голос как способ ввода не зависит от того, какая модель на принимающей стороне. На Mac с валютной картой работает SuperWhisper, кросс-платформенно — Wispr Flow, на Linux open-source — Handy. Я делаю Диктуй — российский вариант на Whisper Large-v3-turbo с рублёвой оплатой и отдельным режимом трансформации (выделил надиктованное ТЗ, голосом сказал «оформи как чистое структурированное задание» — LLM переписала на месте). Сам код голосом диктовать по-прежнему не стоит: ASR ошибается на синтаксисе и именах переменных чаще, чем вы напечатаете руками.
Что попробовать на этой неделе
Если у вас уже есть платная подписка Claude и доступ к Claude Code:
- Обновить Claude Code до
v2.1.154+(claude --version, при необходимостиclaude upgrade) — без этого динамические процессы недоступны. - Включить процессы на своём плане. На Pro — в
/config(по умолчанию выключены), на Max/Team уже включены. - Дать одну крупную задачу полным брифом — например, миграцию или сквозной рефактор с тестами как критерием приёмки. Описать всё сразу, а не короткой командой.
- Попробовать
/effort ultracodeна действительно большой задаче — посмотреть, как Claude сам соберёт оркестрацию. - Сравнить с обычным режимом на той же задаче — окупается ли оркестрация для вашего типа работы или хватает одного агента.
Если хочется проверить именно голосовую постановку задач — у Диктуй free-тариф даёт 30 минут диктовки без карты, этого достаточно надиктовать несколько длинных ТЗ и понять, окупается ли голос под ваш workflow. Разбор четырёх voice-инструментов под Cursor и Claude Code с замерами точности — в отдельной статье, а про встроенный в Claude Code /voice и его границы — в разборе claude code /voice.
Что дальше
Динамические процессы — research preview, и за месяцы они почти наверняка обрастут деталями: больше контроля над оркестрацией, отчётность по под-агентам, выход за пределы Claude Code. Но направление уже видно: рутинную многошаговую работу всё чаще будет планировать и выполнять сама модель, а человек — формулировать задачу и проверять результат. Это тот же сдвиг, про который Andrej Karpathy говорил как про «дирижирование агентами вместо написания кода» — Opus 4.8 просто сделал его инструментальным.
А 9 июня 2026 Anthropic пошла ещё дальше — выпустила Claude Fable 5, модель класса Mythos ступенью выше Opus 4.8 и нового лидера агентного кодинга. Стоит она вдвое дороже, и экономика полного брифа там становится ещё нагляднее: разбор, когда переплата окупается и при чём здесь голос.
Самый практичный вывод на сегодня: ценность сместилась с «написать идеальный короткий промпт» на «поставить полную, недвусмысленную задачу». А это ровно тот формат, который удобнее наговорить, чем напечатать.
Михаил Воинский — основатель Диктуй. Свой опыт постановки задач для динамических процессов Opus 4.8 — какие брифы рой агентов отрабатывает с одного захода, где разваливается на полпути, окупается ли диктовка длинного ТЗ — пишите на support@diktuy.ru или в @diktuy_help.
Часто задаваемые вопросы
Что нового в Claude Opus 4.8 по сравнению с 4.7?
Opus 4.8 вышел 28 мая 2026, через 41 день после Opus 4.7 — заметно более частый цикл обновлений, чем обычно у Anthropic. Прирост по бенчмаркам кодинга, агентных задач и рассуждения; по заявлению Anthropic, модель примерно вчетверо реже пропускает изъяны в коде и чаще сама отмечает места, где не уверена. Но главное архитектурное новшество — динамические рабочие процессы: Claude сам пишет скрипт-оркестратор и запускает рой под-агентов. Ещё из нового: уровень усилия по умолчанию снижен с xhigh (как было у 4.7) до high, добавлены системные сообщения посреди диалога в Messages API, fast mode стал в 3 раза дешевле. Обычная цена и контекстное окно 1M токенов не изменились.
Что такое динамические рабочие процессы (dynamic workflows) простыми словами?
Это способ дать Claude большую задачу и позволить ему самому организовать её выполнение. По документации Claude Code: динамический процесс — это JavaScript-скрипт, который Claude пишет под вашу задачу, а отдельный runtime исполняет его в фоне, пока ваша сессия остаётся отзывчивой. Скрипт сам держит цикл, ветвления и промежуточные результаты — поэтому в контекстном окне модели остаётся только финальный ответ, а не вся история работы роя агентов. Практический результат: Claude Code с Opus 4.8 берётся за миграции на сотни тысяч строк кода от старта до влитого PR, проверяя себя существующим набором тестов. Статус — research preview.
Сколько под-агентов запускает один динамический процесс?
По документации Claude Code — до 16 агентов одновременно (меньше на машинах со слабым CPU) и до 1000 агентов всего за один запуск. Потолок в 1000 — это защита от runaway-циклов, а не типичный масштаб: большинство реальных задач укладывается в десятки под-агентов. Документация отдельно отмечает, что процесс может, например, заставить независимых агентов адверсариально перепроверять находки друг друга — но это опциональный паттерн качества, а не обязательное поведение каждого процесса.
Claude Opus 4.8 подешевел?
Только в части fast mode. Обычный режим стоит столько же, сколько Opus 4.7 — $5 за миллион входных токенов и $25 за миллион выходных, без изменений. Fast mode (та же модель в высокоскоростной конфигурации, до 2,5× скорости вывода) стал в 3 раза дешевле, чем у предыдущих Opus — теперь $10 / $50 за миллион токенов. Частая ошибка русских пересказов — заголовки про «Opus 4.8, который в разы дешевле»: это вводит в заблуждение, обычный режим не дешевел. Fast mode тоже в статусе research preview и требует включённых usage credits.
Что такое ultracode и чем отличается от уровней усилия?
Уровни усилия (effort) у Opus 4.8 — это low, medium, high, xhigh, max; по умолчанию high (у Opus 4.7 было xhigh). В claude.ai те же уровни названы «extra» (это xhigh) и «max». А ultracode — это не шестой уровень модели, а настройка именно Claude Code: команда `/effort ultracode` отправляет модели уровень xhigh и вдобавок даёт Claude право автоматически запускать динамические процессы для крупных задач. Настройка действует только на текущую сессию. Большинство русских разборов смешивают ultracode с уровнем усилия модели — это неточно.
Как получить доступ к Claude Opus 4.8 из России?
Anthropic официально не обслуживает Россию и не принимает российские карты — это подтверждают свежие разборы на vc.ru и Habr от конца мая 2026. Рабочих путей без VPN несколько. Подписку Claude (Pro/Max) на ваш аккаунт оформляют посредники типа Oplatym или GetMeGo за рубли через СБП — именно подписка нужна для Claude Code и динамических процессов. Саму модель по API дают российские агрегаторы (ProxyAPI, GenAPI, Vsegpt, AITunnel) с оплатой в рублях, но это доступ к модели, а не к подписочным фичам Claude Code — оркестрацию через них уточняйте отдельно. Полностью без посредников работают российские модели YandexGPT 5.1 Pro и GigaChat — на сложном reasoning они уступают Opus, но закрывают задачи с конфиденциальными данными.
Стоит ли надиктовывать задачи для агентов голосом?
На длинных брифах — да. Когда работа смещается в сторону оркестрации, человек пишет не короткую команду, а развёрнутое ТЗ с контекстом, ограничениями и критериями приёмки на 200–500 слов. Печатать такой бриф 5–7 минут, надиктовать — 60–120 секунд (речь 130–150 слов в минуту против печати 38–40). И цена неполного брифа выше, чем раньше: процесс, который сам отработает десятки шагов в фоне, на куцем ТЗ уйдёт не туда дороже. Голос помогает не лениться и проговорить все оговорки. Сам код голосом по-прежнему диктовать не стоит — ASR на синтаксисе и именах переменных ошибается чаще, чем вы напечатаете.
Какие бенчмарки у Opus 4.8?
Из официального анонса Anthropic дословно подтверждён результат 84% на Online-Mind2Web (агентные веб-задачи) и качественный тезис про вчетверо меньшую долю пропущенных изъянов в коде. Конкретные числа по SWE-bench Verified (порядка 88% по независимым разборам vellum и llm-stats) в самом анонсе текстом не приведены — основная таблица бенчмарков на странице рендерится скриптом, поэтому такие цифры стоит брать как сторонние оценки, а не как официальную метрику. Если нужен точный показатель — сверяйтесь с System Card модели.